 Cerebras Inference
免费
Cerebras Inference
免费
Cerebras Inference 是 Cerebras 面向生成式 AI 应用提供的高速推理服务,提供 OpenAI 兼容 API、Python/Node.js SDK、Cloud Console、Playground、共享公共端点和企业 Dedicated Endpoints,适合实时聊天、代码生成、Agent 工作流、批量处理与低延迟生产服务。
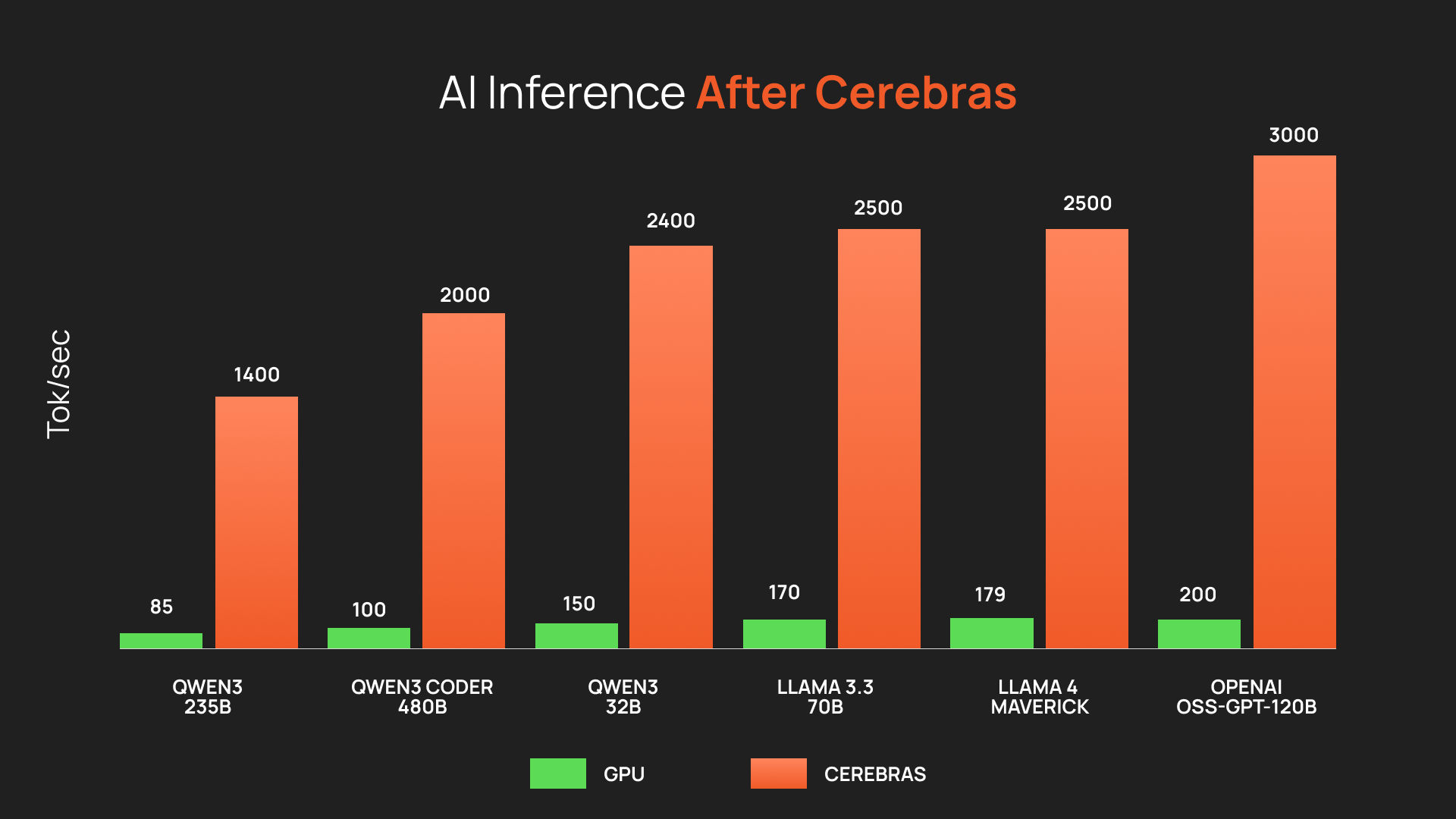
核心参数与定位
Cerebras Inference 是 Cerebras 面向生成式 AI 应用的推理 API 服务,定位不是单一聊天机器人,而是让开发者用低延迟、高吞吐的大模型端点构建实时应用。官网产品页把它描述为面向 generative AI 的高速 inference API,官方文档则把入口拆成 Cloud Console、API Keys、Playground、模型目录、能力文档、API reference、SDK 和 Dedicated Endpoints。
| 项目 | 公开信息 |
|---|---|
| 官网入口 | https://www.cerebras.ai/inference |
| 文档入口 | https://inference-docs.cerebras.ai/ |
| API Base URL | https://api.cerebras.ai/v1 |
| 主要接口 | Chat Completions、Completions、Files、Batch、Models、Metrics、Customer Management API |
| SDK | Python cerebras-cloud-sdk、Node.js @cerebras/cerebras_cloud_sdk |
| 共享端点生产模型 | gpt-oss-120b,120B 参数,约 3000 tokens/s |
| 共享端点预览模型 | zai-glm-4.7、gemma-4-31b(Gemma 标注 Coming soon) |
| 企业形态 | Dedicated Endpoints、reserved capacity、custom weights、Management API、Prometheus metrics |
| 最新公开变更 | 2026-06-01 新增 StepFun Step 3.5 Flash 与 Step 3.7 Flash Dedicated 模型 |
它的关键边界也很明确:共享公共端点更适合快速开发、评估和轻量生产验证;企业 Dedicated Endpoints 才负责保留容量、可预测延迟、生产 SLA、私有高性能端点、自定义权重和更高阶治理。对需要低延迟交互的 Agent、代码助手、检索问答和实时语音链路,Cerebras Inference 的价值主要体现在响应速度和 OpenAI 兼容迁移成本上。
用户与市场认可
Cerebras Inference 的用户画像偏开发者、平台工程团队和企业 AI 应用团队。官方 Quickstart 直接给出 Python、Node.js 和 cURL 三条接入路径,文档还覆盖 OpenAI 兼容、Cline、OpenCode、VS Code、LangChain、PydanticAI、LiveKit、Browserbase、Exa 等工程场景,说明它更像一层可嵌入业务系统的推理基础设施。
开发者认可:OpenAI 兼容 base URL 让已有 OpenAI SDK 项目可以通过替换 base_url 和 API key 迁移,减少重写 client、消息格式和基础错误处理的成本。Python SDK 与 Node.js SDK 的独立发布,也方便团队选择专用 SDK 获取 Cerebras 特有参数。
企业认可:Dedicated Endpoints 面向需要 reserved capacity、稳定吞吐、私有端点、自定义权重和生产保障的客户。官方列出的企业模型家族覆盖 Qwen、OpenAI OSS、MiniMax、Gemma、Llama、Mistral、Z.AI、Moonshot、DeepSeek、StepFun、ByteDance 和 ServiceNow 等,说明产品策略不是只押一个模型,而是把晶圆级推理平台包装成多模型服务层。
市场信号边界:公开资料没有披露独立付费客户数、收入、留存率或行业分布;因此评估时不应把“速度叙事”直接等同于生产可用性结论。更稳妥的方式是用目标模型、目标上下文长度、目标并发和目标响应格式做压测,再结合 rate limit、预算、错误率与官方商务条款判断。
成本优势与计费
Cerebras Inference 的成本优势不是简单的“最便宜 token”,而是用更快生成速度降低实时产品的等待成本、并用共享端点或 Dedicated Endpoints 匹配不同阶段的资源需求。官方模型目录说明公共端点模型可免费使用,但受 rate limits 约束;文档的 rate limits 页面同时列出 Free Trial 与 Developer Pay as You Go 的限制差异。
| 使用层级 | 公开成本/限制信息 | 适合场景 | 注意点 |
|---|---|---|---|
| Free Trial | 公共端点免费使用,受 RPM、TPM、TPH、TPD 限制 | 原型、模型评估、低频 demo | 例如 gpt-oss-120b 免费层公开限制为 5 RPM、30K TPM、1M TPH、1M TPD |
| Developer Pay as You Go | Developer 层按预算使用,文档列出更高 RPM/TPM | 应用开发、早期生产、持续评估 | gpt-oss-120b Developer 层公开限制为 1K RPM、1M TPM |
| Batch API | 私有预览,批量异步处理,官方说明可带来 50% cost savings | 大规模评测、数据标注、批量摘要 | 批处理最长 24 小时完成,SDK 支持在私有预览阶段有限 |
| Dedicated Endpoints | 企业商务沟通,预留容量和私有端点 | 高并发、低延迟、稳定 SLA、私有权重 | 价格、SLA、容量与数据条款需商务确认 |
实际采购时应分开计算三类成本:模型推理 token 成本、响应速度带来的产品体验成本、工程接入和治理成本。对于实时语音、代码补全、Agent 工具链这种“慢一秒就明显掉体验”的应用,Cerebras 的速度可能比单 token 报价更关键;对于离线批处理,Batch API 与异步完成窗口更值得关注。
主要功能
- Chat Completions 与 Completions:提供 OpenAI 风格的聊天和补全接口,适合对话助手、代码生成、摘要、检索增强和多轮工作流。
- Streaming Responses:支持流式输出,适合实时 UI、语音链路和需要快速首 token 反馈的交互体验。
- OpenAI 兼容:可用 OpenAI Python/Node.js client 连接
https://api.cerebras.ai/v1,降低迁移成本。 - Structured Outputs:通过 JSON Schema 和 strict mode 约束输出格式,适合把 LLM 接到业务数据库、审批流和自动化管道。
- Tool Calling:支持让模型请求外部工具调用,并在 API v2 中加强多轮工具消息校验。
- Reasoning 控制:文档覆盖 reasoning models、reasoning_effort、reasoning_format 和 reasoning_logprobs 等能力。
- Prompt Caching:复用重复 prompt 前缀,提升相似请求的 time to first token。
- Batch API 与 Files API:用于异步大规模请求处理,适合评测、标注、批量摘要和实验。
- Cloud Console 与 Playground:管理 API keys、项目、用量、账单、组织访问和交互式模型测试。
- Dedicated Endpoints:企业私有高性能端点,支持 reserved capacity、自定义权重、Management API、Prometheus metrics 和服务层控制。
模型与版本演进
Cerebras Inference 的版本演进分为三条线:API 行为版本、模型目录变化、SDK 版本。API 行为当前最重要的节点是 Version 2:2026-01-21 开放测试,2026-07-21 成为默认版本,影响结构化输出、工具调用、reasoning logprobs 和 Unicode logprobs。
| 时间 | 变化 | 影响 |
|---|---|---|
| 2026-06-01 | Dedicated Endpoints 新增 StepFun Step 3.5 Flash、Step 3.7 Flash | 企业模型家族继续扩展 |
| 2026-05-01 | Projects GA | 可按项目隔离 API keys、用量分析、rate limits 与成员访问 |
| 2026-04-24 | Validation errors 从 422 调整为 400 | SDK 错误类型从 UnprocessableEntityError 变为 BadRequestError |
| 2026-04-22 | 新增 prompt_cache_key |
提升 prompt caching 命中率 |
| 2026-01-21 | API v2 开放测试 | 为 2026-07-21 默认切换做迁移准备 |
| 2025-08-13 | gpt-oss-120b 进入生产支持 |
成为当前共享端点生产模型主线 |
| 2024-10-03 | 早期公共能力更新 | Llama 3.1 高速推理、AutoGen 集成、Playground 登录与参数命名调整 |
从模型目录看,截至 2026-06-28,共享公共端点的生产模型是 gpt-oss-120b;预览模型包括 zai-glm-4.7 和 gemma-4-31b。Dedicated Endpoints 则覆盖更广模型家族,并支持客户自定义权重。这意味着用户在选型时不能只看“Cerebras 支持哪些模型家族”,还要区分“共享公共端点可直接调用”与“Dedicated 企业端点可部署”。
技术优势
高速输出与实时产品适配:模型目录显示 gpt-oss-120b 标称约 3000 tokens/s,zai-glm-4.7 约 1000 tokens/s,Gemma 4 31B 约 1850 tokens/s。对于代码助手、实时客服、语音 Agent 和交互式研究助手,速度优势会直接影响用户是否愿意等待模型完成。
OpenAI 兼容迁移:只需把 OpenAI client 的 base URL 改为 https://api.cerebras.ai/v1,再传入 Cerebras API key,即可复用大量现有消息格式、流式输出和错误处理逻辑。迁移成本越低,团队越容易把 Cerebras 放进 A/B 测试或多供应商路由。
结构化与工具调用能力完整:Structured Outputs、Tool Calling、parallel tool calling、reasoning 控制、logprobs、prompt caching 和 predicted outputs 让它不只是“会聊天”的端点,而是能进入 Agent 编排、业务自动化和评测管线。
企业端点与可观测性:Dedicated Endpoints 提供私有预留容量、Management API、Metrics API 和 Prometheus 兼容指标,能把高吞吐推理纳入企业已有监控和发布流程。对需要稳定延迟和容量保障的生产负载,这比共享端点更关键。
如何使用
使用路径很直接:先在 Cloud Console 注册或登录,创建 API key;然后安装 SDK 或用 cURL 访问 https://api.cerebras.ai/v1/chat/completions;最后在 Playground、日志、rate limit header 和项目用量里观察效果。
| 路径 | 入口 | 典型步骤 | 适合人群 |
|---|---|---|---|
| Python SDK | pip install --upgrade cerebras_cloud_sdk |
设置 CEREBRAS_API_KEY -> 初始化 Cerebras client -> 调用 chat.completions.create |
Python 后端、数据科学、评测脚本 |
| Node.js SDK | npm install @cerebras/cerebras_cloud_sdk@latest |
设置环境变量 -> 创建 client -> 调用 Chat Completions | Web 后端、Node 服务、前端工具链 |
| OpenAI 兼容 | OpenAI SDK + Cerebras base URL | 替换 base URL 与 API key -> 复用现有 OpenAI 风格代码 | 已有 OpenAI 接入的团队 |
| Cloud Console | https://cloud.cerebras.ai/ | 管理 API key、项目、账单、用量、Playground | 产品、工程、平台团队 |
| Dedicated Endpoints | 官网 contact / 企业沟通 | 明确模型、吞吐、延迟、权重、SLA、监控需求 -> 申请专属端点 | 企业生产系统 |
最小可行试点建议选一个延迟敏感场景,例如代码补全、搜索摘要或 Agent 工具调用链路;用同一批 prompt 对比响应时间、首 token 时间、失败率、输出格式稳定性和单位成本。若使用结构化输出或工具调用,应提前用 API v2 header 做兼容测试,因为 2026-07-21 后 v2 会成为默认。
产品定价
官方定价信息分散在模型目录、rate limits、Batch 与 Dedicated Endpoints 文档里。共享公共端点模型可免费使用但受限制;Developer Pay as You Go 提供更高限额;Batch API 面向异步规模化任务;Dedicated Endpoints 需要联系销售确认容量和商务条款。
| 产品形态 | 公开定价/限制 | 关键价值 |
|---|---|---|
| Public Endpoints Free Trial | 免费,受组织级 RPM/TPM/TPH/TPD 限制 | 快速试用、验证速度和模型效果 |
| Developer Pay as You Go | 文档列出 Developer rate limits,费用随预算与使用量变化 | 更高吞吐、适合早期产品接入 |
| Batch API | 私有预览,官方说明批处理可节省 50% 成本 | 评测、标注、批量生成等非实时任务 |
| Dedicated Endpoints | 企业定制 | 预留容量、稳定延迟、自定义权重、生产 SLA |
公开页面没有给出所有模型的固定 token 单价表,也没有公开 Dedicated Endpoints 的标准包年包月价格。因此正式采购前应确认:模型 ID、上下文长度、输入输出 token 单价、免费额度、预算上限、rate limit、SLA、数据保留、日志可见性、区域与合规要求。
应用场景
- 实时聊天与客服助手:低延迟响应能改善多轮对话体验,尤其适合需要流式输出的 Web 或 App 产品。
- AI 编程助手:文档提供 Cline、OpenCode、VS Code 等集成路径,适合代码生成、解释、修复和重构建议。
- Agent 工作流:工具调用、结构化输出、reasoning 控制和高速模型适合多步骤检索、搜索、浏览器自动化和报告生成。
- RAG 与知识问答:Prompt Caching 和
prompt_cache_key适合复用长前缀、知识库说明和系统级上下文。 - 批量评测与数据处理:Batch API 支持 JSONL 文件、最多 50,000 请求、24 小时 completion window,适合离线评测和大规模内容处理。
- 企业高并发推理:Dedicated Endpoints 用于客户面对面产品、稳定吞吐管线、私有权重部署和 Prometheus 监控。
不适合的场景也需要说清:如果团队只需要离线低频生成、对响应时间不敏感,或者必须使用某个共享端点尚未提供的模型,Cerebras 的优势会被削弱;如果需要严格企业合规和私有权重,必须走 Dedicated Endpoints 与商务确认。
适用人群
开发者和初创团队:适合想用 OpenAI 兼容接口快速替换或补充现有推理供应商的人群。先用公共端点验证速度、输出质量和结构化能力,再决定是否进入付费或企业路径。
AI 平台团队:适合需要统一管理 API keys、项目、用量、rate limits、错误处理和多模型路由的团队。Cerebras 的优势在于速度、OpenAI 兼容和企业端点组合。
Agent 与自动化团队:适合构建搜索 Agent、研究 Agent、代码 Agent、语音 Agent 和工具调用链路。高速响应可以缩短多步骤链路的总等待时间。
企业工程团队:适合需要 reserved capacity、生产 SLA、Prometheus metrics、私有端点、自定义权重和更高吞吐的组织。企业用户应重点核对数据处理、日志保留、访问控制、服务区域和支持等级。
谨慎使用边界:如果应用强依赖尚处 preview 的模型、即将变化的 API v2 校验规则、或需要长期固定的模型别名,应在上线前锁定迁移计划和回滚策略。尤其是结构化输出与工具调用用户,应在 2026-07-21 前完成 v2 测试。
总结与展望
Cerebras Inference 的核心价值是把 Cerebras 的高速计算能力包装成开发者可直接调用的推理 API:一边兼容 OpenAI 工作流,降低迁移门槛;一边通过 Dedicated Endpoints 服务企业级低延迟和高吞吐生产场景。当前共享端点主线集中在 gpt-oss-120b,企业端点模型家族更广,产品策略清晰地分成“公共端点快速上手”和“专属端点稳定生产”两层。
接下来最值得关注的是 API v2 默认切换、共享公共端点模型目录扩展、Gemma 4 31B 的上线节奏、Batch API 从私有预览走向 GA、Dedicated Endpoints 的模型家族扩容,以及更细粒度的价格和 SLA 透明度。对准备采用的团队,建议用真实业务 prompt 做延迟、吞吐、格式稳定性和成本压测,再决定把 Cerebras 放在主推理链路、备选供应商,还是专门承担低延迟关键路径。
版本信息
- Cerebras Inference 当前云服务与 Dedicated 模型更新 :Cerebras Inference 作为云端 API 服务滚动更新;官方变更日志最新公开记录为 2026-06-01,新增 StepFun Step 3.5 Flash 和 Step 3.7 Flash Dedicated Endpoints 支持。API v2 已于 2026-01-21 开放测试,并计划在 2026-07-21 成为默认版本;Python SDK 当前公开版本为 1.67.0。
- API Version 2 Available for Testing :API v2 开放测试,加入更严格的结构化输出与工具调用校验、reasoning_logprobs 字段和 Unicode logprobs 修复;2026-07-21 将成为默认版本。
- OpenAI GPT OSS 120B 生产支持 :Cerebras Inference 变更日志记录 gpt-oss-120b 进入生产支持;当前模型目录将其列为共享公共端点的生产模型,标称速度约 3000 tokens/s。
- Cerebras Inference 早期公共 API 能力 :变更日志显示早期公共能力已包含 Llama 3.1 系列高速推理、AutoGen 集成、developer playground 登录优化和 OpenAI 风格参数调整,为后续模型、工具调用和结构化输出扩展奠定基础。
用户评价