 DeepEval
免费
DeepEval
免费
DeepEval 是 Confident AI 团队维护的开源 LLM 评测框架,适合把 RAG、Agent、聊天机器人和模型迁移测试纳入 AI训练模型 质量流程。
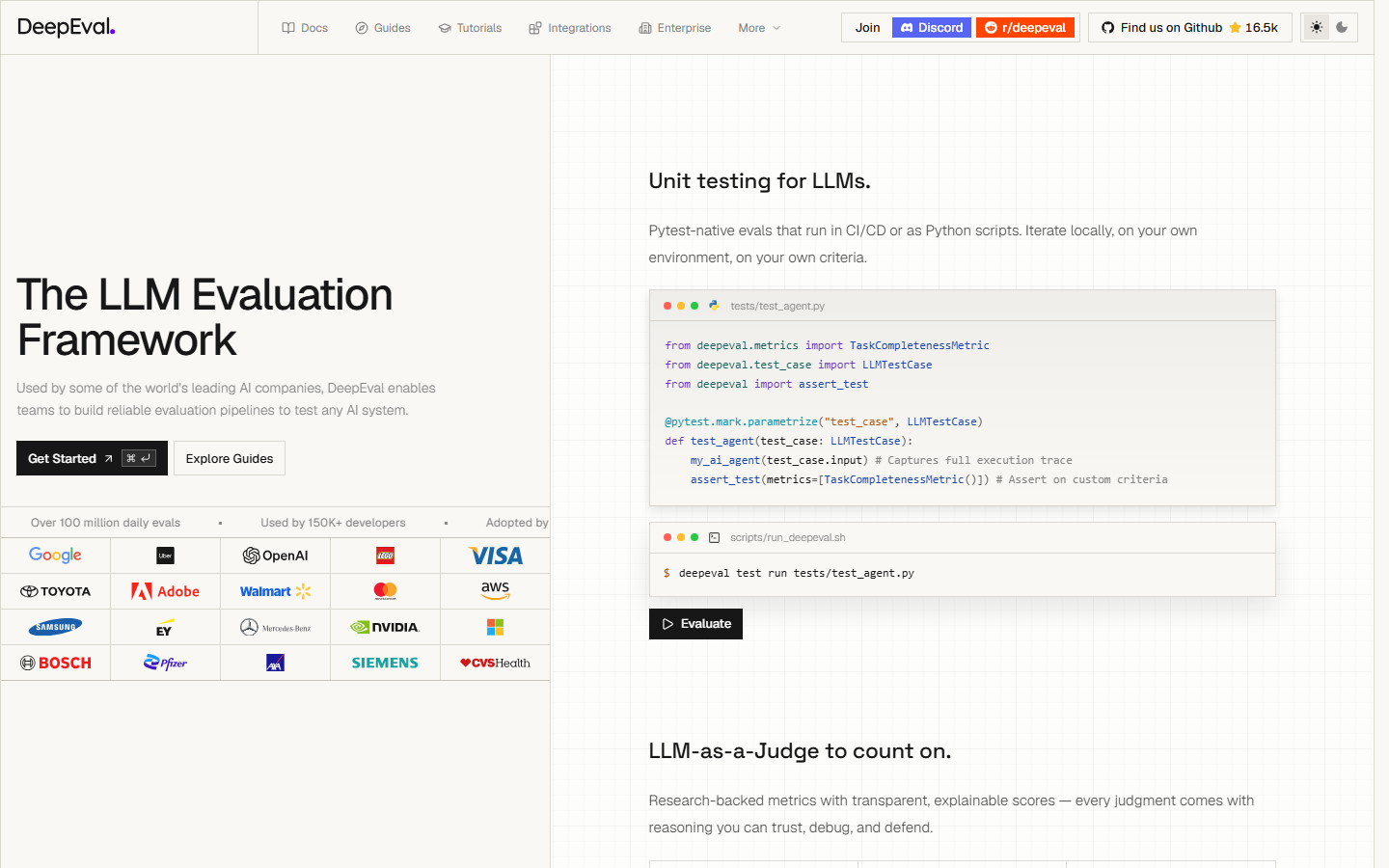
DeepEval 的核心参数与统计
DeepEval 的公开定位是“The LLM Evaluation Framework”。它不是面向终端用户判断文章真伪的 AI 内容检测器,而是给工程团队评测 LLM 应用质量的测试框架:用 Pytest 风格组织测试用例,用指标衡量 RAG、Agent、聊天机器人、多轮对话和模型迁移效果,并把结果接入本地 CI 或 Confident AI 平台。
| 项目 | 公开信息 |
|---|---|
| 产品形态 | 开源 Python 包 + Confident AI 云端质量平台 |
| 官方入口 | Confident AI;DeepEval 文档与产品页为 deepeval.com |
| 开源仓库 | confident-ai/deepeval |
| 许可证 | Apache-2.0 |
| 当前 PyPI 版本 | 4.0.7,上传时间 2026-06-22 |
| Python 要求 | Python >=3.9, <4.0 |
| GitHub 社区规模 | 约 16.4k stars、1.5k forks |
| 核心指标覆盖 | Agentic、RAG、多轮对话、MCP、多模态、幻觉、偏见、毒性、JSON 正确性等 |
| 典型入口 | pip install -U deepeval、deepeval test run、Confident AI 平台 |
分类判断:DeepEval 的工作对象是 LLM 应用质量、测试集、指标、回归与模型/提示词改进,最贴近 ai-model-training。它虽然包含 hallucination、bias、toxicity 等检测指标,但目标是评估模型系统,而不是提供面向内容平台的 AI 生成内容识别服务。
规格边界:DeepEval 能把评测写进代码和 CI/CD,但评测结果仍依赖测试集质量、阈值设置、judge model 与指标选择;对于生产质量治理,仍需要人工标注、日志追踪、版本基线和业务验收共同参与。
DeepEval 的用户与市场认可
DeepEval 的认可度主要来自开源社区、开发者工作流和 Confident AI 的企业平台定位。官方产品页显示 DeepEval 被用于“over 100 million daily evals”,并展示了 Google、OpenAI、Toyota、Adobe、Walmart、Mastercard、AWS、NVIDIA、Microsoft 等采用标识;这些标识可作为官方展示信号,但具体合同范围、部署规模和付费层级未公开。
开源社区:GitHub 仓库公开显示约 16.4k stars 与 1.5k forks,说明 DeepEval 已超出早期实验项目阶段,围绕指标、集成、数据集与测试命令形成了稳定开发者入口。
开发者生态:README 与文档列出 OpenAI、OpenAI Agents、LangChain、LangGraph、Pydantic AI、CrewAI、Anthropic、AWS AgentCore、LlamaIndex 等框架集成。对团队而言,这类集成减少了“先改造应用再评测”的摩擦,更适合在已有 RAG 或 Agent 项目中补质量基线。
企业信号:Confident AI 将自身定位为 AI quality platform,覆盖 benchmark、test、monitor、trace、dataset management 等环节。DeepEval 在本地代码层提供评测执行,Confident AI 则承担团队协作、报告、数据持久化和生产监控的商业化入口。
DeepEval 的成本优势:用开源评测框架把质量门禁前移到研发阶段
DeepEval 的成本优势不是单纯“价格低”,而是把一部分原本依赖人工验收、线上观察或临时脚本的 LLM 质量验证,前移为可重复运行的测试用例。其成本结构需要分三层看:
C 端 / 个人开发者:开源包可通过 PyPI 安装,适合个人项目、Notebook、RAG demo、Agent 原型使用。显性成本主要来自调用 judge model 或被评测模型的 API 费用;如果使用本地模型或统计/NLP 指标,部分评测可降低外部调用成本。
开发者 / API 团队:DeepEval 支持 Pytest 与 CI/CD,能把 deepeval test run 放进 PR、发布前回归或模型切换流程。隐性成本在于维护 goldens、阈值、指标配置与失败分析,但这些成本通常比线上质量事故后补救更可控。
企业 / 私有化团队:Confident AI 定价页公开显示 pricing starts at $0/month,并提供 Free 到 Enterprise 的商业路径;更细的企业价格、座席、SSO、审计、数据保留和合规条款需要商务确认。对企业而言,主要成本不是框架本身,而是测试数据治理、生产日志接入、跨团队指标统一和模型调用预算。
| 成本层级 | 显性费用 | 隐性成本 | 适合阶段 |
|---|---|---|---|
| 个人 / 原型 | 开源包免费;模型调用费另计 | 编写测试样例、选择指标 | 原型验证、课程项目、个人 RAG |
| 开发者 / API | CI 运行资源、模型调用费 | goldens 维护、阈值校准、失败归因 | PR 门禁、模型迁移、发布回归 |
| 企业 / 平台 | Confident AI 商业方案以官方实时页面为准 | 权限、审计、数据治理、跨团队标准 | 生产监控、质量平台化、合规评测 |
DeepEval 的主要功能
DeepEval 的功能围绕“让 LLM 质量可测试、可解释、可回归”展开,核心能力覆盖指标、测试用例、追踪、数据集、集成和平台同步。
- LLM-as-a-Judge 指标:G-Eval、DAG、自定义指标用于把业务标准转成可执行评测,适合没有确定性答案但需要质量判断的场景。
- RAG 评测:Answer Relevancy、Faithfulness、Contextual Recall、Contextual Precision、RAGAS 等指标用于拆分检索质量与生成质量,便于定位是检索上下文问题还是回答生成问题。
- Agentic Metrics:Task Completion、Tool Correctness、Goal Accuracy、Step Efficiency、Plan Adherence、Plan Quality、Tool Use、Argument Correctness 等指标适合评估 Agent 是否完成任务、是否正确调用工具、是否绕路。
- 多轮与 MCP 评测:Knowledge Retention、Conversation Completeness、MCP Task Completion、MCP Use 等指标面向多轮会话和 MCP 服务器调用链路,适合客服、销售、运营助手和工具型 Agent。
- 本地测试与 CI/CD:DeepEval 采用类似 Pytest 的测试方式,可在本地、脚本或 CI 环境运行,减少只靠人工 spot check 的质量盲区。
- Confident AI 平台同步:登录后可把测试结果、报告、数据集和 trace 同步到云端平台,便于团队协作和生产质量观察。
真正落地时,功能选择不宜一次铺满。更稳妥的方式是先为 1 到 2 条高价值链路建立指标基线,例如“RAG 答案必须忠实于检索上下文”或“Agent 必须调用正确工具”,再逐步扩展到多轮、MCP 和生产监控。
DeepEval 的模型与版本演进
DeepEval 的版本演进有两条公开线索:PyPI 包版本用于安装和依赖管理,GitHub Releases 用于查看主要功能节点。当前 PyPI 显示 4.0.7,GitHub 最新 release 显示 v4.0.5;两者不同步时,生产环境应以锁定的包版本和对应变更说明共同校验。
主线版本
- 4.0.7,2026-06-22:PyPI 当前公开版本,适合作为新项目安装基线;支持 Python 3.9 到 3.14。
- v4.0.5,2026-05-28:GitHub Release 节点,新增
claude-opus-4-8模型预设支持,并包含多模态、结构化输出和定价元数据更新。 - v4.0.2,2026-05-13:DeepEval 4.0 节点,引入面向 coding agents 的 eval harness、终端 trace inspection 与 10+ 原生集成。
- v3.9.9,2025-12-01:公开 release 记录聚焦 agentic evals 与多轮 synthetic data generation。
版本使用建议
| 版本节点 | 公开变化 | 使用关注点 |
|---|---|---|
| 4.0.7 | PyPI 当前包版本 | 新项目安装、依赖锁定、Python 版本兼容 |
| v4.0.5 | Claude Opus 4.8 preset | 模型预设、价格元数据、结构化输出场景 |
| v4.0.2 | DeepEval 4.0 能力线 | coding agent eval loop、TUI trace、框架集成 |
| v3.9.9 | Agent 指标与多轮合成数据 | Agent 回归、多轮会话测试集生成 |
高频迭代框架不适合在生产 CI 中无锁定升级。团队应固定 deepeval 版本、记录 judge model、记录指标阈值,并在升级前回放一组稳定 goldens,避免指标逻辑变化被误判为模型质量变化。
DeepEval 的技术优势
DeepEval 的技术优势来自“测试框架化 + 指标体系 + 追踪集成”的组合,而不是单一模型性能。
Pytest 风格机制:把 LLM 输出包装成测试用例,再用 assert_test 和指标阈值判断是否通过。效果是评测可以进入 PR、CI 和发布流程;适用场景是需要持续迭代模型、提示词、RAG chunking 或 Agent 工具链的工程项目。
指标可解释机制:许多指标不仅输出分数,还输出 reason。效果是失败结果更容易定位到回答相关性、事实忠实性、工具调用、步骤效率或角色遵循问题;适用场景是多团队协作调试,而不是只要一个“通过/失败”的黑盒结论。
端到端与组件级评测并存:文档支持把整个 LLM 应用作为黑盒评测,也支持对 trace、span 和组件级调用运行指标。效果是团队可以从用户体验结果一路定位到检索、工具调用或生成节点;适合复杂 RAG、Agent 和多服务编排。
框架集成机制:OpenAI、LangChain、LangGraph、CrewAI、LlamaIndex 等集成降低了接入成本。效果是评测不必重写应用主流程;适用场景是已有 AI 应用补质量治理,而不是从零搭测试平台。
局限边界:LLM-as-a-judge 本身也会受模型偏好、提示词、上下文和阈值影响。关键业务场景仍需要人工标注集、确定性规则、线上监控和回归样例共同校验。
如何使用 DeepEval
DeepEval 的最短路径是安装包、写测试样例、选择指标、运行 CLI。文档给出的基础命令是:
pip install -U deepeval
deepeval test run test_example.py| 入口 | 适合人群 | 典型用途 | 关键前提 |
|---|---|---|---|
| Python 包 | 开发者、算法工程师 | 本地评测、Notebook、单元测试 | Python >=3.9 |
| Pytest / CLI | 工程团队 | CI 回归、发布前质量门禁 | 测试样例与阈值已定义 |
| Confident AI | 团队与企业 | 报告、数据集、trace、生产监控 | 账号、API key、数据治理策略 |
| MCP / IDE 工作流 | Agent 开发者 | 在编辑器内拉取数据、运行评测、检查 trace | Confident AI MCP server 配置 |
典型使用路径可以分三步:先用少量 goldens 覆盖核心业务问题;再为 RAG、Agent 或多轮会话选择对应指标;最后把测试命令接入 CI,并把失败样例沉淀为回归集。对于模型迁移,例如从一个模型切换到另一个模型,DeepEval 的价值在于让迁移前后的质量差异可复现,而不是只依赖人工试聊。
DeepEval 的产品定价
DeepEval 开源框架本身以 Apache-2.0 许可发布,PyPI 包可免费安装。商业化部分主要落在 Confident AI 平台,官方定价页公开描述为 pricing starts at $0/month,并面向个人开发者到企业团队提供扩展路径;具体套餐额度、团队功能和企业条款以官方实时页面为准。
- 开源框架:显性订阅成本为 0,模型调用、CI 资源和内部维护成本另计。
- 云端平台:Free 路径适合小规模验证;团队协作、生产监控、审计、数据保留等更可能进入付费或企业方案。
- 企业采购:SSO、SOC2、私有网络、审计日志、数据驻留与合同 SLA 等信息需要商务确认,不宜从公开页面推断价格。
| 产品层 | 公开价格信号 | 主要价值 | 未公开项 |
|---|---|---|---|
| DeepEval OSS | 免费开源 | 本地评测、CI 测试、指标库 | 模型调用费不包含在框架内 |
| Confident AI Free | $0/month 起 | 云端报告、轻量团队试用 | 额度与限制以实时页面为准 |
| Confident AI Enterprise | Contact sales / Demo 路径 | 团队治理、生产监控、合规能力 | 座席、保留期、SSO、SLA、私有化条款 |
评估成本时,应同时估算 judge model 调用量、评测频率、goldens 数量和 CI 并发。对于高频发布团队,评测集规模需要分层:PR 阶段跑小而关键的冒烟集,夜间或发布前跑更完整的回归集。
DeepEval 的应用场景
DeepEval 更适合“持续变化但必须稳定交付”的 LLM 应用,而不是一次性 demo。
- RAG 知识库质量回归:评测答案是否相关、是否忠实于检索上下文、检索片段是否覆盖预期信息。收益是把 chunking、embedding、rerank 和提示词变更的影响量化。
- Agent 工具调用验收:检查 Agent 是否完成任务、是否调用正确工具、参数是否正确、步骤是否冗余。收益是把“看起来会用工具”变成可回归测试。
- 模型迁移与提示词改版:比较不同模型、不同 prompt 或不同系统架构在同一组 goldens 上的表现。收益是降低模型替换时的主观判断风险。
- 多轮客服与销售助手:评测知识保持、对话完整性、角色遵循与任务完成情况。收益是提前发现多轮上下文漂移和角色偏离。
- 生产质量监控:与 Confident AI 平台结合后,可把离线评测、trace 与线上响应监控串起来。收益是让质量问题从个案反馈变成趋势指标。
这些场景的共同前提是业务团队能定义“好回答”或“成功任务”的标准。缺少业务标准时,评测框架只能产出分数,不能替代质量共识。
DeepEval 的适用人群
DeepEval 对三类人群最有价值。
- AI 应用开发者:需要把 RAG、聊天机器人或 Agent 的质量写进测试流程,尤其适合已经使用 Python、Pytest 或 CI/CD 的团队。
- 机器学习 / LLM 平台团队:需要统一不同项目的评测指标、测试集、模型迁移基线和发布门禁,减少各业务线各写一套脚本。
- QA 与产品质量负责人:需要用可解释分数和报告追踪 LLM 系统是否满足业务标准,而不是只靠人工体验判断。
- 企业 AI 治理团队:需要把评测、监控、审计和数据集管理接入统一平台时,可关注 Confident AI 的商业能力。
不太适合的情况是:团队只做一次性演示、没有稳定测试样例、没有明确质量标准,或产品并非 Python/CI 友好型工程。此时先建立业务验收标准,比直接引入完整评测框架更重要。
DeepEval 的总结与展望
DeepEval 的核心竞争力在于把 LLM 应用评测做成工程化测试框架:开发者可以用熟悉的测试文件、CLI 和 CI 管道评估 RAG、Agent、多轮对话和模型迁移;Confident AI 则把这些评测结果扩展到团队协作、报告和生产监控。对希望从“人工试聊”升级到“可回归质量门禁”的团队,它是一个明确的入场选择。
当前限制也需要正视:PyPI 与 GitHub Release 节奏并不总是完全一致;公开定价未披露所有企业条款;LLM-as-a-judge 指标需要校准,不能直接替代人工标注和业务验收;官方展示的客户标识不能等同于具体部署规模。采购和落地时,应先选 1 到 2 条高风险链路试点,记录基线分数、人工干预率、误判样例和模型调用成本,再决定是否扩展到全量 CI 与企业平台。
版本信息
- DeepEval 4.0.7 :PyPI 当前公开包版本,支持 Python 3.9 到 3.14,延续 DeepEval 4.x 的 Agent 评测、追踪与 CI 测试能力。
- Opus 4.8: Day 0 Support :GitHub Releases 公开的 4.x 版本节点,新增 claude-opus-4-8 模型预设支持,并包含多模态与结构化输出相关定价元数据。
- DeepEval 4.0 :GitHub Releases 公开的 DeepEval 4.0 节点,引入面向 coding agents 的 eval harness、终端 trace inspection 与 10+ 原生集成。
用户评价