 HoneyHive
免费
HoneyHive
免费
HoneyHive 是面向 AI Agent 和 LLM 应用的观测与评测平台,覆盖生产追踪、在线评测、离线实验、数据集、告警、提示词管理和企业级部署,适合需要把 AI 系统从原型推进到可监控、可回归、可治理生产环境的团队。
HoneyHive
HoneyHive 的核心定位与参数
HoneyHive 是一个面向生产级 AI Agent 与 LLM 应用的观测、评测和持续改进平台。它不是只记录 API 调用日志的轻量面板,而是把分布式追踪、在线评测、离线实验、数据集管理、提示词管理、告警和企业级部署放在同一条工程链路中,帮助团队回答三个关键问题:线上发生了什么、一次改动是否真的变好、哪些失败样本应该进入下一轮测试。
| 项目 | 信息 |
|---|---|
| 官方名称 | HoneyHive |
| 产品定位 | AI observability and evaluation platform |
| 官网 | https://www.honeyhive.ai/ |
| 文档 | https://docs.honeyhive.ai/ |
| 主要对象 | 生产 AI Agent、RAG、LLM 应用、自动化工作流 |
| 核心范式 | Evaluation-Driven Development,基于评测驱动 AI 系统迭代 |
| 技术底座 | OpenTelemetry、Python SDK、TypeScript SDK、API、集成式 instrumentor |
| 最新公开版本 | HoneyHive v2,2026-05-05 发布 |
从工具目录视角看,HoneyHive 最适合归入 AI 开发与治理工具:它服务的不是终端内容生成,而是帮助开发者、平台团队和企业 AI 团队把模型调用、工具调用、上下文、反馈和质量指标变成可追踪、可比较、可审计的生产资产。
HoneyHive 的市场认可与适用阶段
HoneyHive 官网将自己描述为 production agents 的 observability layer,文档则进一步定义为用于 tracing、evaluating、monitoring 和 improving AI agents 的完整平台。这意味着它更适合已经进入真实用户、真实数据或准生产环境的 AI 应用,而不是只做早期 demo 的轻量玩具链路。
| 阶段 | HoneyHive 的价值 | 典型判断点 |
|---|---|---|
| 原型验证 | 快速接入 tracing,定位提示词、模型和工具调用中的明显问题 | 是否能在 5-10 分钟内看到第一条 trace |
| 测试迭代 | 将失败样本沉淀为 dataset,用 experiment 比较不同方案 | 是否能用固定评测集衡量改动收益 |
| 生产监控 | 对成本、延迟、成功率、质量得分和异常趋势进行观察 | 是否能及时发现质量下降或错误激增 |
| 企业推广 | 控制敏感数据、权限、部署位置和跨团队治理 | 是否需要 RBAC、自托管、混合部署和审计能力 |
对企业团队来说,HoneyHive 的核心卖点在于把“AI 质量”从主观体验转成工程指标:同一条生产 trace 可以被调试、标注、回放、评估,并进入后续回归测试。这样一来,Agent 的改进不再只依赖人工感觉,而能围绕真实失败样本形成持续反馈闭环。
HoneyHive 的成本结构与商业边界
HoneyHive 定价页展示了 Developer 与 Enterprise 两类主要方案。Developer 层为 Free,面向个人开发者和早期项目,官方页面列出 10K events per month、最多 5 个用户、单 workspace、30 天数据保留,以及完整 observability and evaluation suite。Enterprise 面向大型组织,强调自定义用量、无限用户与 workspace、Custom Roles、Enterprise SSO/SAML、专属支持、SLA、混合或自托管部署。
| 方案 | 公开信息 | 适合对象 |
|---|---|---|
| Developer | 免费,无需信用卡,10K events/月,最多 5 用户,单 workspace,30 天保留 | 个人开发者、早期验证、小团队试点 |
| Enterprise | 商务沟通,自定义用量,SSO/SAML,专属支持,混合或自托管可用 | 大型企业、受监管业务、多团队生产部署 |
| 隐性成本 | 埋点改造、评测集建设、权限设计、评估函数维护、数据治理 | 任何生产级 AI 系统都需要纳入预算 |
实际采购时不能只比较订阅价格。HoneyHive 的收益来自减少线上黑盒问题、缩短回归定位时间、降低错误 Agent 上线风险;成本则来自接入、数据标注、指标口径对齐和组织流程建设。对于高风险行业,能否支持数据平面留在客户环境中,往往比面板功能多少更关键。
HoneyHive 的主要功能
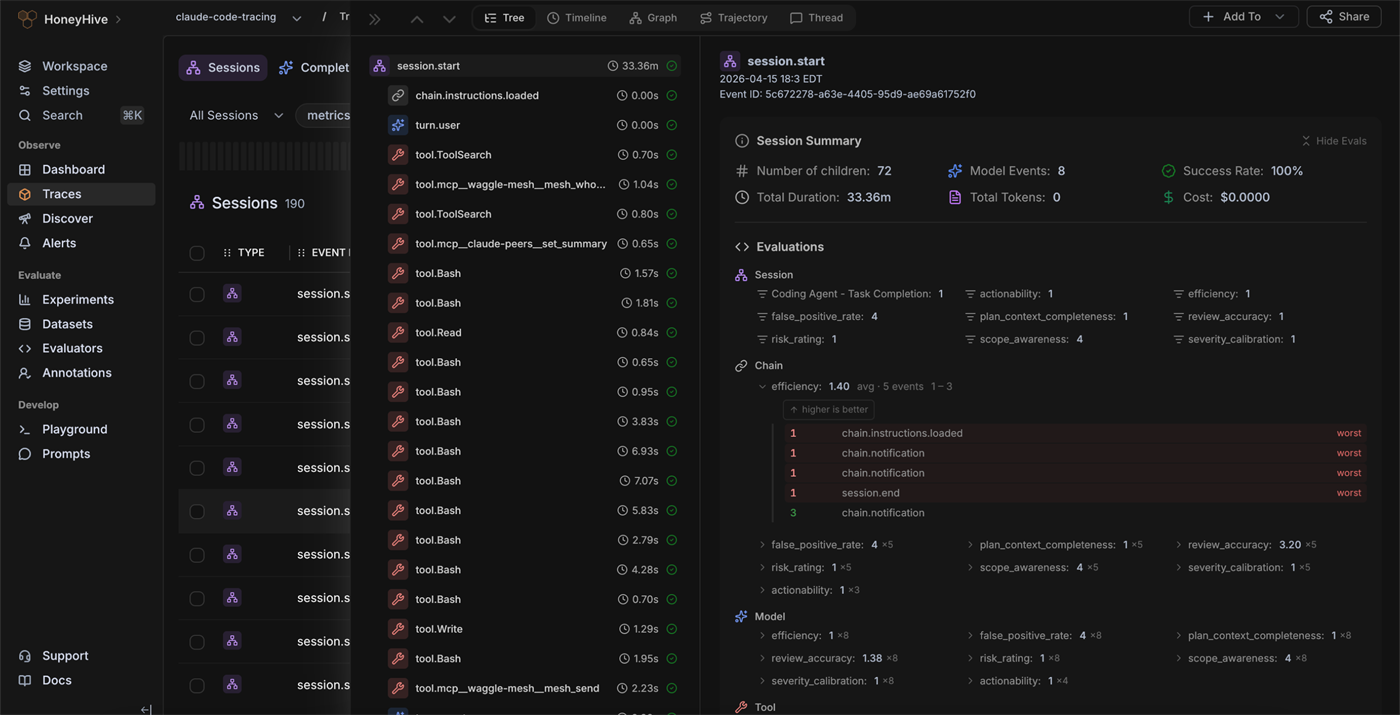
HoneyHive 的能力可以按 AI 应用生命周期拆成四组。第一组是生产观测:通过 tracing 捕获 LLM 调用、工具调用、链式步骤、会话上下文、成本、延迟和反馈,让团队能从单次异常回到完整执行过程。第二组是评测与实验:通过 datasets、evaluators 和 experiments 比较提示词、模型、RAG 检索、Agent 策略或代码改动。
第三组是监控与告警:将质量、错误、延迟、成本、反馈等指标放入 dashboard 和 alert,帮助团队在用户大量感知问题之前发现漂移。第四组是迭代管理:通过 prompt management、annotation queues、human evaluation、LLM-as-judge 和代码评估器,把线上样本变成可复用测试资产。
| 功能模块 | 作用 | 适用问题 |
|---|---|---|
| Traces | 查看每次 LLM、工具和链路执行细节 | 为什么这次 Agent 回答错了 |
| Trajectories | 分析长运行 Agent 的循环、停滞和异常路径 | Agent 为什么卡在某一步 |
| Experiments | 对比不同版本的提示词、模型和流水线 | 改动是否真的提升质量 |
| Datasets | 管理测试样本、失败案例和标注数据 | 如何复用线上问题做回归 |
| Evaluators | 用代码、LLM-as-judge 或人工评分衡量质量 | 如何把主观质量变成指标 |
| Alerts | 监控质量下降、错误激增和指标漂移 | 如何及时发现线上退化 |
| Prompt Management | 管理、版本化和部署提示词 | 如何减少提示词散落在代码里 |
HoneyHive 的技术架构与 v2 演进
HoneyHive v2 是一次平台级重构。官方 v2 文章将重点放在企业生产 Agent 的敏感日志边界上:Agent trace 中常常包含真实对话、工具输入输出、PII/PHI/PCI、内部提示词和业务上下文,而这些内容又恰好是评测质量所必需的数据。v2 因此采用控制平面与数据平面分离的架构。
控制平面负责项目结构、评估器定义、告警规则、schema、身份、权限和审计等非敏感元数据;数据平面保存原始日志、输入输出、数据集和评测计算。这样的设计让企业可以选择多租户 SaaS、Dedicated SaaS、Hybrid 或 Self-hosted,把敏感数据和评测计算放在更符合合规要求的位置。
| 版本 | 重点变化 | 影响 |
|---|---|---|
| v1 / GA | 支持团队将 LLM 应用从原型推进到生产的观测与评测 | 适合早期生产化和单团队使用 |
| v2 | 控制平面/数据平面拆分、Custom Roles、Python/TypeScript SDK、CLI、Trajectories | 更适合企业级、跨团队、受监管 AI Agent |
| v2 后续路线 | Coding agent integrations、增强在线评测、更高阶 TypeScript SDK | 扩展到开发代理和更自动化的质量闭环 |
这一架构选择很务实:AI 评测无法简单依赖脱敏摘要,因为很多质量判断必须看原始上下文。HoneyHive v2 的方向是把敏感数据留在应该留的位置,同时让非敏感指标和治理信息可被平台团队统一管理。
HoneyHive 的集成生态
HoneyHive 建立在 OpenTelemetry 之上,官方文档强调 model agnostic、framework agnostic 和 runtime agnostic。它可以与 OpenAI、Anthropic、Bedrock、开源模型等模型提供方配合,也覆盖 LangChain、CrewAI、Google ADK、AWS Strands、OpenAI Agents SDK 等 Agent 或应用框架。
接入方式上,开发者可以使用 Python SDK、TypeScript SDK、OpenTelemetry collector、REST API 或自动 instrumentor。官方 tracing quickstart 给出的路径非常直接:创建项目、获取 API key、安装 honeyhive 与相关 instrumentor,初始化 tracer,然后在 HoneyHive 的 Traces 页面查看结果。
这种生态策略的好处是减少供应商锁定。团队不必为了观测和评测强制绑定某个模型、某个 Agent 框架或某种运行时;对平台团队而言,统一 trace schema 和评测流程比统一底层模型更有长期价值。
HoneyHive 的使用流程
使用 HoneyHive 的推荐流程可以概括为“先观测,再评测,最后闭环”。第一步是在关键 Agent 或 LLM 应用中接入 tracing,捕获会话、span、工具调用、模型响应、成本、延迟和元数据。第二步是把真实问题样本整理为 datasets,并定义代码评估器、LLM-as-judge 或人工标注规则。
第三步是在 experiment 中比较不同 prompt、model、retrieval、tool policy 或代码版本,确认改动对指标的影响。第四步是将评测接入 CI/CD 或发布流程,避免回归。第五步是在生产环境持续运行 online evaluations、dashboards 和 alerts,让线上反馈继续进入下一轮数据集与实验。
| 流程 | 关键动作 | 产出 |
|---|---|---|
| 接入 | 初始化 tracer,接入模型/框架 instrumentor | 可查看的生产 trace |
| 标注 | 收集用户反馈和专家判断 | 更可靠的质量标签 |
| 评测 | 运行 experiment,对比多个版本 | 可量化的质量结论 |
| 发布 | 将评测结果纳入 CI 或发布门禁 | 降低上线回归风险 |
| 监控 | 配置 dashboard 与 alert | 更快发现线上退化 |
HoneyHive 的数据安全与企业部署
HoneyHive 的企业价值很大程度来自部署和治理能力。官网定价页和 v2 文章都强调 Enterprise 场景,包括 Enterprise SSO/SAML、Custom Roles、专属支持、SLA、混合部署和自托管。定价页 FAQ 还说明数据在静态和传输中加密,并提到 SOC 2 Type II、GDPR、HIPAA 合规,以及通过第三方审计进行渗透测试。
对高监管行业,HoneyHive v2 的控制平面/数据平面拆分尤其重要。平台团队可以集中管理项目、评估器、权限和审计,而业务单元或区域团队可以把敏感 trace 和评测计算留在自己的数据边界内。这样既保留统一治理,也避免把所有原始 Agent 日志集中到单一共享环境。
落地时仍需要团队自行定义权限边界、数据保留策略、脱敏策略、评测数据用途和审计流程。HoneyHive 提供平台能力,但 AI 数据治理的责任仍需要组织、法务、安全和业务共同承担。
HoneyHive 的典型应用场景
HoneyHive 适合任何“AI 输出质量需要被持续证明”的场景。客服 Agent 可以用它追踪多轮对话、工具调用和人工反馈;金融或保险流程可以用它评估理赔、风控、贷款辅助决策中的一致性和错误模式;RAG 系统可以用它比较检索策略、上下文相关性和回答忠实度;代码或运营 Agent 可以用它分析长任务执行轨迹和失败环节。
在产品团队中,HoneyHive 可以帮助 PM 和工程师围绕同一套指标讨论“是否变好”。在平台团队中,它可以成为统一的 AI 可观测层,避免每个业务线各自拼日志、表格和人工复盘。在合规团队中,它提供的是更清晰的审计入口:谁访问了什么、哪些数据被评估、哪些版本触发了异常。
最值得优先试点的是高频、可定义成功标准、失败成本较高但仍可控的流程。例如客服回答质量、工单分类、RAG 检索问答、内部知识助手、销售线索处理、自动化研究 Agent 等。
HoneyHive 的适用人群
HoneyHive 对四类人最有价值。第一类是 AI 应用工程师,他们需要看懂每一次模型和工具调用为什么失败。第二类是 ML/LLMOps 或平台工程团队,他们需要统一观测、评测、告警和部署治理。第三类是产品和运营团队,他们需要把用户反馈与业务质量指标纳入迭代。第四类是安全、合规和企业架构团队,他们关注数据边界、权限、审计和自托管能力。
不太适合的情况也很明确:如果项目还停留在一次性 prompt demo,没有真实用户、没有质量指标,也没有上线计划,HoneyHive 的治理能力可能显得偏重。相反,一旦团队开始面对“模型换了会不会退化”“Agent 为什么偶发失败”“怎样证明新版更可靠”“敏感 trace 应该放在哪里”这类问题,HoneyHive 的价值会迅速显现。
从采购和试点角度,建议先选择一个业务闭环清晰的 Agent,定义 3-5 个核心指标,再接入 tracing 和 experiment。不要一开始就试图监控所有 AI 系统;先让一个高价值流程跑通观测、评测、数据集和告警,收益会更清楚。
HoneyHive 的总结与选型建议
HoneyHive 的核心优势是把 AI Agent 的生产观测和质量评测连成一个持续改进系统。它既能让工程师看清单次 trace,也能让团队用 datasets 和 experiments 判断改动是否有效;既覆盖开发阶段的 prompt 迭代,也覆盖生产阶段的 online evaluations、dashboard 和 alert。
如果团队正在把 LLM 应用或 Agent 推向生产,并且已经遇到质量漂移、长链路调试、评测标准不统一、回归测试薄弱、敏感日志治理等问题,HoneyHive 是值得优先评估的工具。它的 v2 架构尤其适合对权限、数据驻留、自托管和跨团队治理有要求的企业环境。
选型时建议重点验证四件事:接入现有模型和框架的成本、评估器是否能表达业务质量、生产 trace 是否符合安全策略、定价和部署方式是否匹配预期用量。只要这四点成立,HoneyHive 就不仅是一个可视化面板,而是 AI 工程团队的质量基础设施。
版本信息
- HoneyHive v2 :HoneyHive v2 是平台级重构版本,官方说明包含新的架构、Custom Roles、新 Python 与 TypeScript SDK、HoneyHive CLI、长运行 Agent 的 Trajectories 等能力,并强调面向企业级生产 Agent 的观测与评测闭环。
- HoneyHive v2 :新架构将控制平面与数据平面分离,强化 RBAC、企业部署、SDK、CLI、Trajectories 与 Agent 开发生命周期支持。
- HoneyHive GA / v1 :v2 发布文章提到 HoneyHive 在上一年 GA,v1 面向团队从 LLM 应用原型推进到生产的观测与评测工作流,后续客户将迁移到 v2。
用户评价