 Laminar
免费
Laminar
免费
Laminar 是一款面向 AI agents 的开源 AI智能体 可观测性平台,围绕 tracing、evals、AI monitoring、SQL 查询、dashboards、datasets 与自托管部署,帮助团队定位 agent 失败原因并持续迭代。
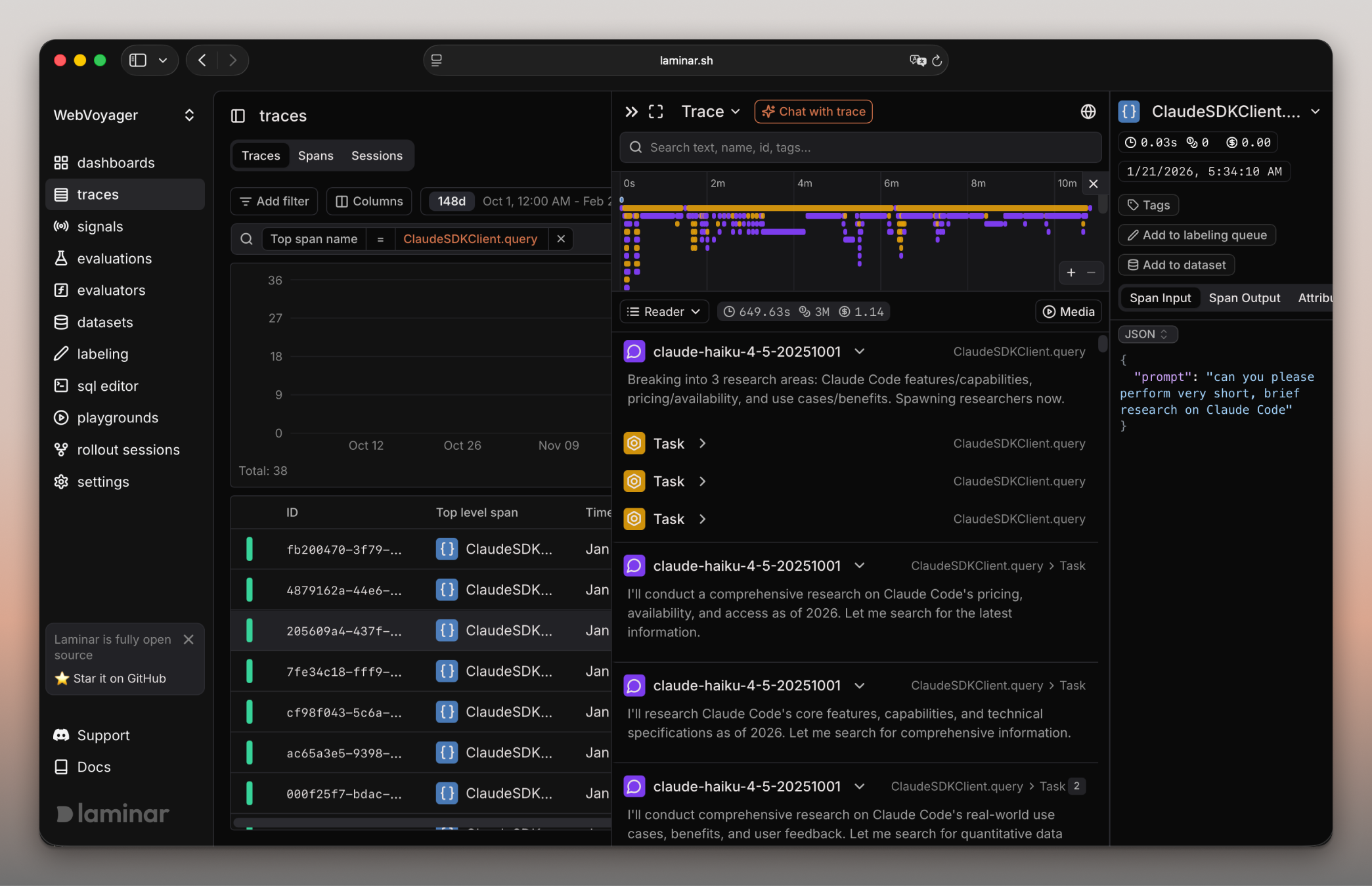
Laminar 的核心参数与统计
Laminar 是一款面向 AI agents 的开源可观测性平台,官方仓库说明把它定位为 “open-source observability platform purpose-built for AI agents”。它不是通用聊天机器人,也不是单纯的模型训练框架,而是把 agent 运行链路中的 traces、evals、signals、datasets、SQL 查询和 dashboards 放进同一套 LLMOps 工作台。
| 项目 | 公开信息 |
|---|---|
| 官方定位 | Open-source observability platform purpose-built for AI agents |
| 核心能力 | Tracing、Evals、AI monitoring、SQL access、Dashboards、Datasets、Annotation |
| 技术路线 | OpenTelemetry-native tracing SDK、Rust 后端组件、自定义 realtime engine、gRPC exporter |
| 集成对象 | Vercel AI SDK、Browser Use、Stagehand、LangChain、OpenAI、Anthropic、Gemini 等 |
| 部署路径 | Managed platform、自托管 Docker Compose、生产环境 full compose |
| 开源许可 | Apache-2.0 |
| GitHub 社区 | 约 3,026 stars、210 forks、86 open issues |
| 最新公开版本 | v0.2.0,2026-06-18 发布 |
定位边界:Laminar 的优势在 agent 链路观测与评估闭环,不负责直接替代 LLM、向量数据库或业务编排框架。团队如果只有一次性 prompt 调试需求,使用它会显得偏重;如果 agent 已经进入多工具、多模型、多步骤执行阶段,它的 trace 与 eval 视角才会更有价值。
Laminar 的用户与市场认可
Laminar 的市场信号主要来自开源社区、YC 背书和开发者生态,而不是公开披露的企业客户数。官方仓库显示项目属于 YC S24,并且仓库描述、README 与公开截图都围绕 agent 失败诊断和迭代效率展开,说明它的目标用户不是泛办公人群,而是正在把 AI agents 投入生产或准生产环境的研发团队。
开源热度:GitHub API 显示 lmnr 仓库约 3,026 stars 和 210 forks,已经形成可观察的开发者关注度。这个规模不等同于商业采用量,但足以说明它在 LLM observability 与 agent evals 场景中有持续外部验证。
产品信号:官方 README 把 traces、evaluations、signals、datasets、SQL editor、dashboards 同列为核心能力,产品截图中也能看到 traces、signals、evaluations、datasets、labeling、sql editor、playgrounds 等导航项。这种信息架构显示 Laminar 试图覆盖从运行记录到数据集沉淀、从问题检测到评估回归的完整闭环。
不确定项:官方未公开累计用户数、付费客户数或收入规模,因此这些维度应保留为未公开。采购或技术选型时,更适合以自托管可运行性、SDK 覆盖范围、trace 查询性能和 eval 回归流程作为验证依据。
成本优势:用开源自托管降低 Agent 可观测性的试点门槛
Laminar 的成本优势不在“零成本”,而在于同一产品同时提供 managed platform 与开源自托管路径。研发团队可以先用官方托管平台快速接入,再按数据边界、合规要求或成本结构迁移到自托管;也可以直接从 Docker Compose 本地启动轻量版本验证。
| 成本层级 | 可用路径 | 成本构成 | 边界说明 |
|---|---|---|---|
| C 端/个人 | 官方托管入口、开源本地部署 | 以官方实时页面为准;本地部署需机器与维护时间 | 更适合学习 tracing/evals 概念,不适合作为个人内容生产工具 |
| 开发者/API | TS SDK、Python SDK、OpenTelemetry-native tracing、CLI evals | 模型调用费用、存储与查询资源、CI 执行成本 | SDK 免费不代表整体运行免费,trace 量和保留周期会影响基础设施成本 |
| 企业/私有化 | Self-hosted Docker Compose、production full compose、managed platform | 服务器、Postgres/ClickHouse 等依赖、权限治理、SSO/合规、运维人力 | 企业功能、额度、支持和合同条款以官方实时页面为准 |
显性费用:开源仓库采用 Apache-2.0 许可,SDK 与自托管路径降低了试点门槛。隐性费用:真实成本主要来自 trace 数据存储、查询性能、评估集维护、CI/CD 集成和团队内部治理。对 agent 平台而言,观察链路越细,数据价值越高,但存储和筛选规则也越需要设计。
Laminar 的主要功能
Laminar 的功能围绕“发现 agent 为什么失败,并把修复变成可回归的流程”组织,核心不是单点监控,而是 trace、eval、dataset 和 signal 的联动。
- Tracing:通过 OpenTelemetry-native SDK 采集 agent 执行链路,官方 README 提到一行代码可自动追踪 Vercel AI SDK、Browser Use、Stagehand、LangChain、OpenAI、Anthropic、Gemini 等集成。适合排查多步骤 agent 中的工具调用、模型响应、跨度耗时和异常位置。
- Evals:提供可扩展 SDK 和 CLI,可在本地或 CI/CD 中运行评估,并用 UI 可视化 eval 结果和比较变化。适合把一次性人工判断转成版本回归门禁。
- AI monitoring / Signals:允许用自然语言描述事件,跟踪 agent 的问题、逻辑错误和自定义行为。它的价值在于把“看日志”升级为对业务语义问题的持续检测。
- SQL access:内置 SQL editor 可查询 traces、metrics、events,并可从查询批量创建 datasets,也可通过 API 使用。适合分析大量 span 数据和沉淀评估样本。
- Dashboards 与 datasets:dashboard builder 可基于 traces、metrics、events 和 SQL 构建看板;datasets 与 annotation UI 则服务于 eval 数据生产。
落地时最需要验证的是三点:SDK 是否覆盖现有 agent 技术栈,trace 数据是否足够解释失败原因,eval 数据集能否被团队持续维护。缺少这三点,平台容易停留在“看起来很完整”的仪表盘层面。
Laminar 的模型与版本演进
Laminar 本身不是大模型,因此“版本演进”主要看开源仓库 release、SDK 集成和产品模块迭代。GitHub Releases 显示最新公开版本为 v0.2.0,发布时间为 2026-06-18;同一 release changelog 涉及 traces chat、debugger、SQL、self-hosted、Better Auth、Slack OAuth broker、OTEL self-tracing 等大量工程更新。
主线版本
- v0.2.0(2026-06-18):最新公开 release。变化覆盖 traces chat OSS、debugger rework、LLM streaming、self-hosted Slack OAuth broker、Better Auth 迁移、SQL endpoint 限制、OTEL self-tracing、configurable Postgres schema 等,说明项目已经从基础 tracing 向调试、部署治理和自托管企业场景扩展。
- v0.1.46(2026-06-18):v0.2.0 changelog 中的直接对比基线,适合作为 0.1.x 到 0.2.x 的迁移观察点。
- v0.1.45(~2026-06):GitHub tags 公开的历史节点,官方暂无精确发布日期,主要用于观察 0.1.x 系列版本连续性。
版本选择建议:生产环境不宜只追随最新 tag。更稳妥的方式是固定 release,使用一组代表性 agent trace 和 eval dataset 做回归,确认 SDK、数据库 schema、查询性能和权限配置都稳定后再升级。
Laminar 的技术优势
Laminar 的技术优势来自“agent 专用观测模型 + 可自托管工程栈 + 数据可查询性”的组合,而不是某个单一模型能力。
OpenTelemetry-native tracing:机制上复用观测生态中的 trace/span 思维,把 agent 的模型调用、工具调用和函数执行纳入统一链路。效果是问题定位从“读散落日志”变成“沿 span 还原执行路径”;适用场景是多模型、多工具、多步骤 agent。
Rust 与实时引擎:官方 README 提到后端采用 Rust、自定义 realtime engine、超快全文搜索和 gRPC exporter。机制上强调高吞吐和实时查看,效果是更适合 trace 量较大、调试窗口较短的场景;适用对象是在线 agent、浏览器 agent、客服 agent 和自动化研究 agent。
SQL 直达数据层:内置 SQL editor 和 API 访问让 traces、metrics、events 不只停留在 UI 过滤器里。机制上把观测数据变成可分析数据,效果是可以从错误样本中批量创建 datasets,再反向用于 eval;适合已有数据分析能力的研发和平台团队。
自托管路径:Docker Compose 和 production full compose 让团队可以控制数据面。效果是降低敏感 agent 数据进入第三方托管环境的阻力;适用场景包括内部知识库 agent、企业流程 agent 和包含客户数据的业务 agent。
如何使用 Laminar
Laminar 的使用入口分为托管平台、自托管部署和 SDK/CLI 接入三层。官方 README 给出的最快路径是使用 managed platform;自托管则可 clone 仓库后通过 Docker Compose 启动,轻量版本默认可在本地浏览器访问。
| 使用入口 | 典型步骤 | 适合对象 | 验收重点 |
|---|---|---|---|
| Managed platform | 创建项目、生成 project API key、接入 SDK | 想快速验证 traces/evals 的团队 | 首条 trace 是否可见,agent 关键 span 是否完整 |
| Self-host Docker Compose | clone 仓库、docker compose up、配置 SDK baseUrl 与端口 | 需要控制数据面的研发团队 | 服务可用性、数据库持久化、升级迁移、权限边界 |
| TS / Python SDK | npm add @lmnr-ai/lmnr 或 pip install lmnr[all],初始化 Laminar | 已有 agent 代码的开发者 | 自动 instrumentation 覆盖率、手动 observe 注解成本 |
| Evals / CI | 使用 SDK 或 CLI 运行 evals,本地或 CI/CD 中比较结果 | 需要回归评估的团队 | 评估集质量、阈值规则、失败样本回收 |
最小试点可以从一个失败率较高的 agent workflow 开始:接入 trace,标注失败样本,转成 dataset,再在每次 prompt、tool 或 model 变更后跑 eval。这样能验证 Laminar 的核心闭环,而不是只验证截图里的仪表盘是否好看。
Laminar 的产品定价
Laminar 的公开资料同时指向托管平台和开源自托管,但具体托管套餐、额度、保留周期和企业支持条款需要以官方实时页面为准。文档不应把未公开或会变动的价格写成固定事实。
C 端/个人:个人开发者可通过官方入口体验 managed platform,也可用开源仓库在本地运行轻量环境。实际免费额度、项目数、trace 保留期和执行量限制以官方实时页面为准。
开发者/API:SDK 与开源代码降低了接入成本,但 API 层面的真实成本包括模型调用、trace 存储、查询资源、CI eval 执行和数据保留。团队应按“每天 trace 数、span 深度、评估频率、保留周期”估算资源。
企业/私有化:自托管可控制数据面,但企业级 SSO、审计、私有部署支持、合规和 SLA 条款需要商务确认。若 agent 处理客户数据或内部敏感流程,价格评估应把安全审查、运维值守和数据库容量纳入总成本。
Laminar 的应用场景
Laminar 更适合 agent 已经进入工程化阶段的场景,尤其是“失败原因很难从单条日志看清楚”的系统。
- 浏览器/网页操作 agent 调试:Browser Use、Stagehand 等集成使其适合追踪网页任务中的模型判断、工具调用和页面操作。核心收益是定位失败发生在感知、规划、工具执行还是输出解析。
- 客服与内部流程 agent 监控:多步骤客服、工单分流、内部审批 agent 往往涉及模型调用、业务 API 和规则判断。Laminar 可用 signals 追踪逻辑错误,用 dashboards 观察问题趋势。
- LLM 应用回归评估:prompt、模型版本和工具 schema 变化会造成行为漂移。Laminar 的 evals、datasets、annotation 与 CI/CD 适合把关键样本沉淀为持续回归集。
- Agent 运行数据分析:SQL editor 让 traces、metrics、events 可以被查询和批量转成 datasets。适合平台团队分析高耗时 span、常见失败类型和模型成本结构。
不适合的场景包括纯聊天 demo、一次性提示词实验、没有生产 trace 的早期原型,以及只需要传统 APM 的普通 Web 服务。
Laminar 的适用人群
Laminar 的强适配人群是已经在构建 agent 应用、并且需要把调试经验沉淀为可复用观测和评估资产的团队。
- AI 工程师与 agent 开发者:需要知道每次 agent 失败发生在哪个 span、哪个工具或哪个模型输出。Laminar 能把链路展开成 trace,并支持手动 observe 包裹关键函数。
- LLMOps / 平台团队:需要统一监控多个 agent 项目的运行质量、构建 dashboard、查询 trace 数据并治理自托管部署。Laminar 的 SQL、dashboards 和自托管路径更贴近平台职责。
- QA 与评估负责人:需要把人工标注、失败样本和回归评估连接起来。Laminar 的 datasets、annotation 与 evals 可服务于“上线前发现行为退化”的流程。
- 产品与业务负责人:适合在成熟团队中查看质量趋势和失败类型,不适合直接把 Laminar 当无代码业务工具使用。
前置条件是团队至少具备基本工程接入能力、能维护 SDK/API key、能定义 eval 样本和业务失败标准。没有这些基础时,Laminar 的能力会被低效使用。
Laminar 的总结与展望
Laminar 的核心价值在于把 AI agent 的运行观测、失败分析、评估回归和数据沉淀放到同一个开源平台里。相较只做日志采集或只做 eval 的工具,它更强调从 trace 到 dataset、从 signal 到 dashboard 的闭环;相较纯托管平台,它又提供自托管路径和 Apache-2.0 开源基础。
当前限制也很清晰:公开定价细节、客户采用规模和企业合同条款仍需以官方实时页面为准;开源项目迭代频繁,生产部署需要固定版本并进行回归;trace 数据一旦变多,存储、保留周期、PII 处理和查询成本都会成为实际治理问题。
落地建议是先选择 1 到 2 条高价值 agent workflow 做试点,接入 TS 或 Python SDK,验证 trace 完整性、失败样本标注效率、eval 回归可重复性和 SQL 查询性能;当试点能稳定解释失败原因并减少回归风险,再扩展到更多 agent 项目。企业采购前应重点确认托管额度、数据保留、SSO/审计、自托管支持、PII 处理和最新 release 在自身技术栈中的稳定性。
版本信息
- Laminar v0.2.0 :GitHub Releases 公开的最新版本,包含 traces chat、debugger rework、self-hosted Slack OAuth broker、Better Auth 迁移、SQL 与 tracing 相关改进等。
- Laminar v0.1.46 :GitHub tag 与 v0.2.0 changelog 对比中的上一公开版本节点,用作 v0.2.0 的直接历史基线。
- Laminar v0.1.45 :GitHub tags 公开的历史版本节点,暂无官方精确发布日期,适合用于回溯 0.1.x 系列演进。
用户评价