 Predibase
Predibase
Predibase 是面向开源大模型微调与生产推理的 AI训练模型 平台,公开文档覆盖 adapters、fine-tuned inference、private deployments、Deployment Health Analytics 等能力。2025 年 Rubrik 宣布收购并在交易完成后推出由 Predibase AI infrastructure 支撑的 Agent Rewind,使 Predibase 从独立微调平台进一步进入企业级 Agent 安全与恢复场景。
Predibase 的核心参数与统计
Predibase 的核心定位是“开源大模型 fine-tuning + 推理部署基础设施”,更接近 AI训练模型,而不是通用数据处理工具。Predibase 文档中的 Fine-tuned Adapters 明确写到,用户可以通过 SDK 或 UI fine-tune adapters,训练完成后可在对应 base model deployment 上进行 adapter inference;Adapters 则把 adapters 定义为参数高效的微调方式,并列出 LoRA、Turbo、Turbo LoRA 等类型。
| 项目 | 公开信息 |
|---|---|
| 产品形态 | 企业级 LLM fine-tuning、adapter inference 与部署运维平台 |
| 主要入口 | Web 控制台、Python SDK、API / deployment endpoint |
| 核心对象 | Base model、adapter、deployment、deployment health metrics |
| 微调方式 | LoRA、Turbo、Turbo LoRA 等 adapter 路线 |
| 推理方式 | Fine-tuned adapter inference、private deployments、serverless fine-tuned endpoints |
| 运维指标 | 请求量、吞吐、LoRAX inference time、队列时长、GPU replicas、GPU utilization |
| 最新公司状态 | 2025-08-12 后归入 Rubrik,Agent Rewind 由 Predibase AI infrastructure 支撑 |
| 公开精确客户数 | 未公开 |
| 公开独立定价 | 未公开,以官方实时页面或商务沟通为准 |
定位边界:Predibase 不是面向普通 C 端用户的聊天产品,也不是简单的数据标注工具。它的价值集中在已经有训练数据、评测集、模型部署目标的团队,帮助这些团队把开源模型适配到具体任务,并在推理阶段用统一 deployment 和健康指标管理成本、吞吐与稳定性。
Predibase 的用户与市场认可
Predibase 的市场认可主要来自两条线:一是围绕开源模型微调与 LoRAX / adapter serving 的技术积累,二是 Rubrik 在 2025 年把它纳入企业 AI 与数据安全体系。Rubrik 在 2025-06-25 新闻稿 中称其收购目标是加速 agentic AI adoption,并提到 Predibase 与 Rubrik 结合后将面向模型、数据、准确性、成本、性能和数据治理形成组合能力。
企业化信号:Rubrik 在 2025-08-12 新闻稿 中宣布完成收购后推出 Agent Rewind,并说明该产品由 Predibase AI infrastructure 支撑,用于让企业查看 AI agents 的动作并回滚不期望的更改。这说明 Predibase 的能力已经从模型基础设施扩展到企业级 agent 安全、审计和恢复场景。
开源生态信号:Predibase 技术路线与 Ludwig、LoRAX、LoRA adapters 等开源生态关系紧密。公开页面没有稳定披露 Predibase 平台的总用户数或 ARR,因此不应把第三方传闻写成确定事实;更可靠的判断是,Rubrik 收购和官方文档持续维护表明其能力已进入企业生产级 AI 基础设施叙事。
Predibase 的成本优势:用 adapter 与弹性 deployment 降低定制模型的长期推理成本
Predibase 的成本逻辑不是“单次调用绝对最低”,而是通过 adapter、共享 base model、自动扩缩容和 deployment health metrics,把“训练一个专用模型并长期运行”的总成本降下来。Rubrik / Predibase 的 Deployment Health Analytics 文章明确把请求量、吞吐、队列时长、GPU replicas、GPU utilization 放在同一套监控里,并说明 deployment 可以按阈值增加 replicas,也可以在需求降低时 scale down,甚至配置为 scale down to zero replicas。
| 成本层级 | 当前公开信息 | 适用判断 |
|---|---|---|
| C 端 / 个人 | Predibase 不是典型个人订阅工具,公开页面没有稳定披露个人套餐 | 个人用户更适合用文档、SDK 或开源组件学习路线,正式平台费用以官方实时页面为准 |
| 开发者 / API | 文档覆盖 SDK、UI、deployment client、adapter inference;Serverless Fine-tuned Endpoints 文章提到按 token 查询 fine-tuned LLM | 适合按项目试点微调模型,真实成本由训练量、推理量、GPU deployment 和 token 计费共同决定 |
| 企业 / 私有化 | Private deployments、Deployment Health Analytics 与 Rubrik Agent Cloud 形成企业化部署与治理路径 | 适合需要 VPC / 私有部署、监控、审计、agent 回滚和商务支持的组织,合同条款需商务确认 |
成本机制:adapter 微调避免为每个任务复制完整大模型权重;deployment health metrics 让团队能观察吞吐和 GPU 利用率;autoscaling 与 scale-to-zero 把低峰期闲置 GPU 成本压低。这些机制只有在请求量波动明显、模型数量较多或长期服务成本较高时才充分体现价值。
Predibase 的主要功能
- Adapter fine-tuning:Predibase 文档把 adapters 定义为参数高效微调方式,支持用少量任务专属参数适配模型,而不是更新全部权重;这适合分类、抽取、客服、结构化生成等任务。
- Fine-tuned adapter inference:文档说明 fine-tuned adapters 可以在对应 base model deployment 上调用,所有 deployments 都支持 adapter inference out of the box,减少为每个 adapter 单独重建服务的复杂度。
- Private deployments:Private deployments 文档覆盖 adapter 合并、preloaded adapters 等配置,适合对性能、隔离和部署控制更敏感的企业场景。
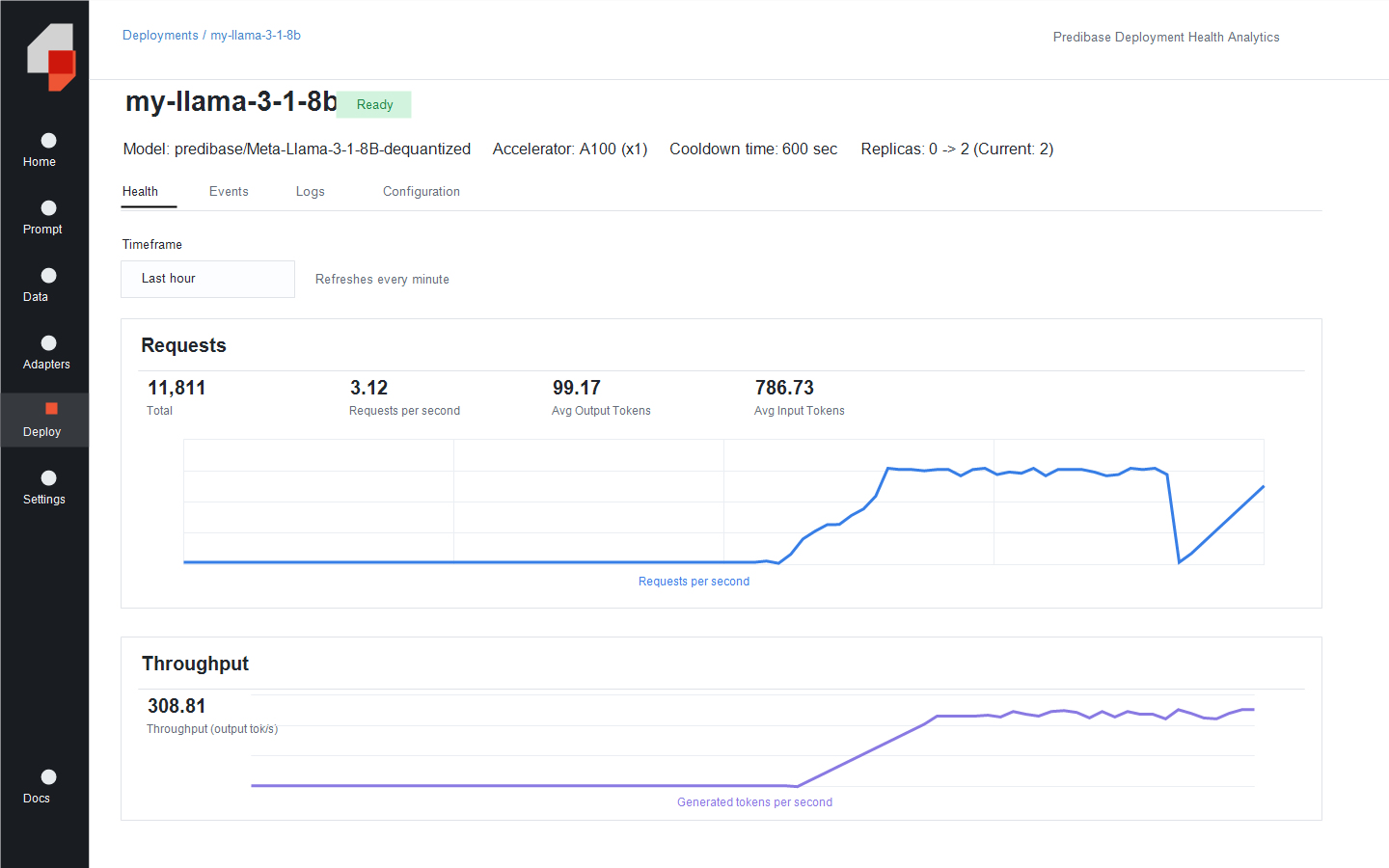
- Deployment Health Analytics:博客公开展示 Predibase 控制台中的请求量、吞吐、LoRAX inference time、队列时长、replicas 与 GPU utilization,用于管理性能和成本之间的平衡。
- Agent Rewind 基础设施:Rubrik 完成收购后推出 Agent Rewind,公开说明其由 Predibase AI infrastructure 支撑,用于追踪、审计并回滚 AI agents 的异常动作。
Predibase 的模型与版本演进
Predibase 不是传统“客户端版本号”产品,版本演进更适合按公开能力节点理解:从微调与服务开源模型,到 deployment health analytics,再到 Rubrik 收购后的 Agent Rewind / Agent Cloud 方向。
| 时间 | 节点 | 变化重点 |
|---|---|---|
| ~2024-02 | Serverless Fine-tuned Endpoints | 公开介绍无需为 fine-tuned LLM 单独启动专用 GPU deployment 的 serverless 查询方式 |
| 2024-09-11 | Deployment Health Analytics | 公开展示 deployment 运行健康指标,用于观察请求、吞吐、队列、replicas 与 GPU utilization |
| 2025-06-25 | Rubrik 签署收购协议 | Predibase 被纳入 Rubrik 企业 AI、数据与安全战略 |
| 2025-08-12 | Rubrik 完成收购并推出 Agent Rewind | Predibase AI infrastructure 成为 Agent Rewind 的底层能力之一 |
演进含义:早期 Predibase 解决的是“如何更省成本地 fine-tune 与 serve 开源模型”,收购后的重点增加了“如何让企业安全地运行 AI agents”。这对采购和技术选型的影响是:单纯寻找开源微调库的团队,可以关注 SDK、adapter 和 LoRAX 生态;需要企业级 agent 审计与恢复的团队,则需要同时评估 Rubrik Agent Cloud 的平台能力。
Predibase 的技术优势
机制:adapter 参数高效微调。Predibase 的 adapter 路线通过少量新增参数适配模型任务,效果是减少训练和存储开销;适用场景是同一个 base model 需要服务多个业务任务,而每个任务都需要不同输出风格或专业知识。
机制:动态 adapter 推理与共享 deployment。Fine-tuned adapter inference 让训练后的 adapter 可在 base model deployment 上调用,效果是减少为每个模型副本准备独立部署的成本;适用场景是企业内部有多个细分任务模型,需要统一部署与扩缩容。
机制:Deployment Health Analytics。把请求量、吞吐、队列时长、GPU replicas 与 utilization 放在一个控制台里,效果是把性能问题和成本问题同时暴露出来;适用场景是生产环境流量波动、需要按 SLA 调整 replicas 或 autoscaling 参数的团队。
机制:与 Rubrik 数据安全能力结合。收购后 Predibase infrastructure 与 Rubrik 的数据治理、恢复和 Agent Rewind 结合,效果是把模型运行与 agent 操作审计放入企业恢复链路;适用场景是金融、医疗、IT 运维等对错误回滚和审计责任要求高的组织。
如何使用 Predibase
Predibase 的典型使用路径从数据和任务目标开始,而不是从模型聊天入口开始。团队需要先准备训练样本、评测集和目标 base model,再决定使用 SDK、UI 或 private deployment。
- 确认任务类型:分类、抽取、客服自动化、结构化生成、专有知识问答或 agent 动作评估。
- 选择 base model:根据文档支持的模型列表和上下文长度、许可证、LoRA / Turbo LoRA 支持情况选择模型。
- 训练 adapter:通过 UI 或 SDK 运行 fine-tuning,记录训练数据版本、评测集和 adapter 版本。
- 部署与调用:在 base model deployment 上使用 fine-tuned adapter inference,或按性能需求配置 private deployment。
- 观察运行指标:用 Deployment Health Analytics 检查请求量、吞吐、队列、replicas 和 GPU utilization,再调整 autoscaling 阈值。
落地时需要把“离线评测”和“线上监控”一起设计。只看训练集指标容易高估效果;只看线上吞吐又可能忽略模型准确性,因此 Predibase 更适合有 MLOps / LLMOps 基础的团队。
Predibase 的产品定价
Predibase 当前没有在公开页面稳定展示一套可直接复用的独立价格表,收购后企业入口也与 Rubrik Agent Cloud / Agent Rewind 更紧密相关。定价和合同条款应以官方实时页面、控制台账单或商务确认为准。
个人与试验:若只是验证 adapter 微调路线,成本主要来自训练和推理资源;公开文档可用于理解 SDK / UI 路径,但平台额度、试用和计费细则需要实时确认。
开发者与 API:Serverless fine-tuned endpoints 的公开文章强调按 token 查询 fine-tuned LLM,适合不希望为每个 fine-tuned model 长期维护专用 GPU 的团队;实际成本取决于 token、并发、GPU deployment 与流量波动。
企业与私有化:Private deployments、Agent Rewind 和 Rubrik Agent Cloud 相关能力更偏企业采购,通常需要确认 VPC / 私有部署、SSO、审计、SLA、数据保留、agent 回滚范围和支持等级。
Predibase 的应用场景
- 企业专有任务微调:把通用开源模型微调到合同抽取、工单分类、客户支持、合规问答等具体任务上,验收重点是任务准确率、幻觉率和人工复核比例。
- 多 adapter 统一推理:多个业务线共享同一 base model,但各自维护 adapter,验收重点是 adapter 切换、吞吐、延迟与 GPU 利用率。
- 生产部署性能优化:利用 Deployment Health Analytics 观察请求高峰、队列时长和 replicas 变化,验收重点是 SLA、峰值成本和低峰 scale-down 效果。
- 企业 agent 风险控制:在 Rubrik Agent Rewind 场景中追踪 AI agents 的动作并支持回滚,验收重点是动作可见性、审计链路、恢复粒度和业务系统覆盖范围。
Predibase 的适用人群
- AI 工程师与 LLMOps 团队:需要把开源模型从实验室微调推进到可观测、可扩缩容的生产推理环境。
- 企业平台 / 数据团队:已有私有数据和治理要求,希望在模型训练、部署和审计之间建立统一流程。
- 业务自动化与 Agent 团队:希望把定制模型作为 agent 系统底层能力,并关注 agent 错误操作的可追踪与可恢复。
不适配边界也很清楚:没有训练数据、没有评测指标、只想直接使用通用聊天助手的团队,不应把 Predibase 作为第一选择;如果只是一次性小脚本推理,完整 deployment / monitoring / enterprise governance 也可能带来额外复杂度。
Predibase 的总结与展望
Predibase 的核心价值在于把开源模型微调、adapter 推理和部署健康管理合到一条生产链路中。它的技术重点不是“又一个大模型”,而是让企业能用自己的数据训练更贴合任务的小型或中型模型,并通过 deployment metrics 控制吞吐、延迟和 GPU 成本。Rubrik 收购后,Predibase 的角色进一步上移到企业 agent 安全基础设施,尤其是 Agent Rewind 这类需要可见性、审计和恢复能力的场景。
当前限制与不确定项包括:独立 Predibase 平台的公开定价不稳定披露,收购后部分商业入口可能迁移到 Rubrik;公开客户数量和平台总体使用量未披露;Agent Rewind 的覆盖系统、回滚粒度和合同条件需要商务确认。落地建议是先用一个可量化任务做 adapter 微调试点,同时保留基线模型对照;当任务准确性、线上吞吐和单位成本都达到阈值后,再扩展到多 adapter、多业务线或 Rubrik Agent Cloud 的企业级治理场景。
版本信息
- Rubrik Agent Rewind powered by Predibase AI infrastructure :Rubrik 宣布完成对 Predibase 的收购并推出 Agent Rewind,该产品由 Predibase AI infrastructure 支撑,用于为企业 AI agents 的操作提供可见性与回滚能力。
- Rubrik to acquire Predibase :Rubrik 宣布签署收购 Predibase 的协议,目标是将 Predibase 的模型与推理基础设施用于推动企业 agentic AI 从试点走向规模化生产。
- Deployment Health Analytics :Rubrik / Predibase 博客公开介绍 Deployment Health Analytics,用于监控请求量、吞吐、LoRAX inference time、队列时长、GPU replicas 与 GPU utilization 等部署健康指标。
- Serverless Fine-tuned Endpoints :暂无官方精确日期;Rubrik / Predibase 博客公开介绍 Serverless Fine-tuned Endpoints,用于按 token 查询 fine-tuned LLM,而不必为每个 fine-tuned model 单独启动专用 GPU deployment。
用户评价