OpenRouter推出Fusion API:"拼好模"以一半成本实现Fable 5级智能
OpenRouter推出Fusion API多模型协同系统,Gemini 3 Flash+Kimi K2.6+DeepSeek V4 Pro组合以约Claude Fable 5一半成本实现接近性能,OpenRouter接入模型数突破400。
OpenRouter推出Fusion API:多模型"拼好模"以一半成本叫板Fable 5
全球最大AI大模型API聚合平台 OpenRouter 于 6 月 14 日推出 Fusion API——一个多模型协同系统,将用户输入同时发给多个模型,由审查模型汇总分析后生成统一回答。从基准跑分看,部分多模型组合已超越 Anthropic 旗舰 Claude Fable 5。
Fusion 的工作链路分三步:第一步并行发送请求让多个模型各自作答;第二步由审查模型读取回答并输出结构化分析;第三步由调用模型依据分析内容生成最终答复。
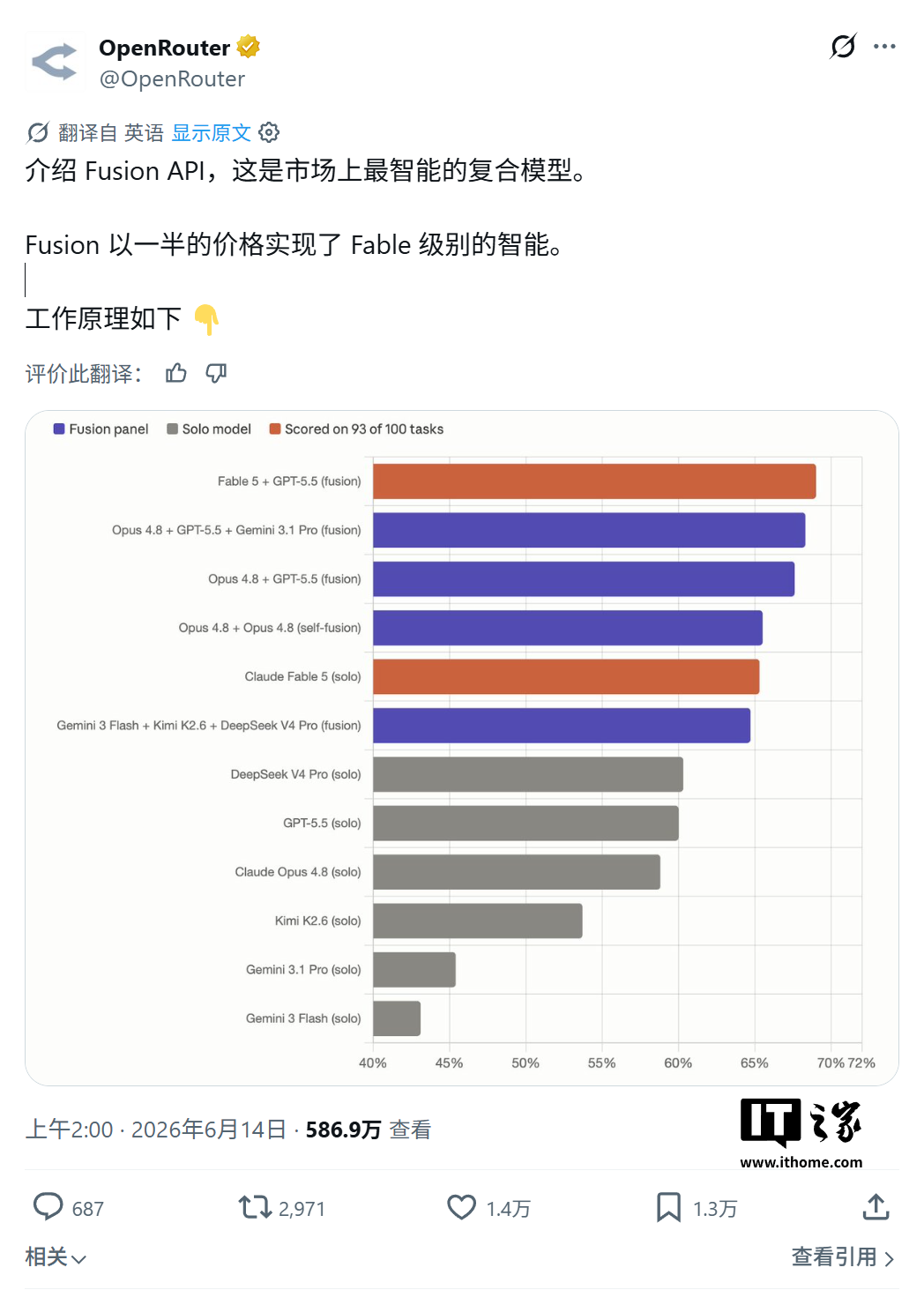
在 SWE-Bench 基准测试中的完整排名:
| 类型 | 模型组合 | 得分 |
|---|---|---|
| Fusion | Fable 5 + GPT-5.5 | 69.0% |
| Fusion | Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro | 68.3% |
| Fusion | Opus 4.8 + GPT-5.5 | 67.6% |
| Fusion | 双 Opus 4.8 | 65.5% |
| Solo | Claude Fable 5 | 65.3% |
| Fusion | Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro | 64.7% |
| Solo | DeepSeek V4 Pro | 60.3% |
| Solo | GPT-5.5 | 60.0% |
| Solo | Claude Opus 4.8 | 58.8% |
| Solo | Kimi K2.6 | 53.7% |
| Solo | Gemini 3.1 Pro | 45.4% |
| Solo | Gemini 3 Flash | 43.1% |
最引人关注的是 "经济型组合"——Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro——以约 Claude Fable 5 一半的成本,将基准测试分数差距控制在仅 1%(64.7% vs 65.3%)。更值得注意的是,这个组合中的三个模型单独跑分都不高(43.1%、53.7%、60.3%),但通过 Fusion 的审查-合成机制,协同后的效果大幅超越了各自的上限。
还有两个反直觉的发现:第一,Fable 5 + GPT-5.5 组合(69.0%)不仅超越了 Fable 5 单独跑分(65.3%),也超越了单独跑分都是 60.0% 左右的 GPT-5.5,说明即便是最强模型也能通过多模型协同获得额外增益;第二,双 Opus 4.8 组合(65.5%)竟然略微超越了 Fable 5 单独跑分(65.3%),意味着两个次强模型的协同在特定场景下可以超越单一最强模型。
OpenRouter 同时还宣布接入模型数突破 400 个。Fusion API 的本质是"用廉价算力换智能"——通过并行调用多个低价模型并用一个审查模型做裁决,开辟了一条绕过单一供应商锁定、以更低成本获取旗舰级 AI 能力的新路径。
用户评价