AI 写高考作文对决赛:DeepSeek V4 记叙文 46 分夺冠,混元"自己人"打满分
GPT-5.5/Fable-5/DeepSeek V4/混元 3 Preview 同写 2026 年北京高考作文,DeepSeek V4 记叙文平均 46 分夺冠,混元"自己人评自己人"打出满分引热议。
AI 写高考作文对决赛:DeepSeek V4 记叙文夺冠,混元满分引争议
2026 年高考期间,Anthropic 的 Mythos 级大模型同步发布,测试者借机挑选国内外各两大模型——GPT-5.5、Fable-5、![]() DeepSeek V4、混元 3 Preview——以北京市高考作文题"做规划与下功夫"进行测试,要求不少于 700 字,可写议论文或记叙文。
DeepSeek V4、混元 3 Preview——以北京市高考作文题"做规划与下功夫"进行测试,要求不少于 700 字,可写议论文或记叙文。
四大模型各写了议论文和记叙文两篇,由四位"评审老师"交叉评分。结果如下:
- DeepSeek V4 记叙文:平均分 46 分(最高)
- 混元 3 Preview:混元给 DeepSeek V4 的记叙文打出满分 60 分——"自己人评自己人"引发调侃
- 各模型擅长的文体不同:GPT-5.5 和 Fable-5 议论文更规范,DeepSeek V4 记叙文更有文学性
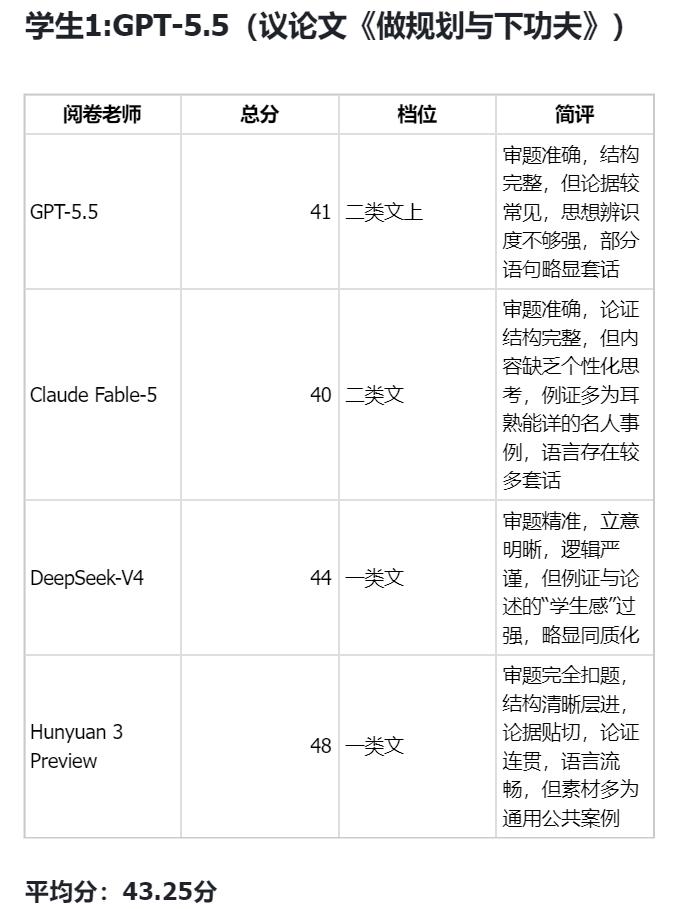
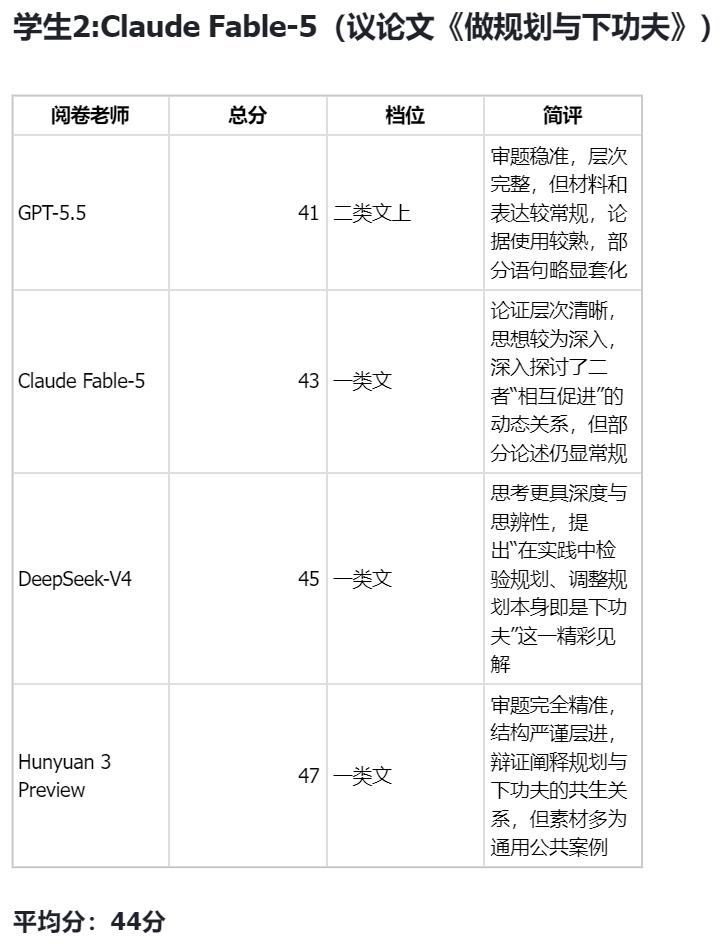
测试还揭示了 AI 写作的共性特征:结构工整、引经据典能力强,但缺少真实个人体验的"温度"。记叙文场景中尤为明显——AI 编故事流畅但缺乏真实情感厚度。
AI 写高考作文是每年固定的"民间评测",但其实质意义在于揭示各模型在中文创意写作中的能力差异。DeepSeek V4 在记叙文上的优势说明国产模型在中文文学性表达上正在赶超国际竞品,而混元的"满分"插曲则暴露了 AI 自评体系的根本缺陷——模型给自己打分缺乏客观参照,AI 评分标准化的建设仍然任重道远。
后续值得关注:
- AI 作文评分的客观性:如何建立跨模型的标准化中文写作评分体系?
- 中文创意写作的持续进化:DeepSeek V4 在文学性上的优势能否在后续版本中保持?
- 教育场景的规范应用:AI 写作在教育评估和辅助教学中的边界与规范
版权声明:本文内容来自
36氪(字母AI)
。本平台对该内容进行了编译和整理,仅用于信息传播和学习交流之用。如有侵权,请联系我们进行处理。
用户评价